Revolutionizing Drug Discovery: How the CataPro Deep Learning Model Predicts Enzyme Kinetics with Unprecedented Accuracy
This article provides a comprehensive analysis of the CataPro deep learning model, a cutting-edge tool for predicting enzyme kinetic parameters (kcat).
Revolutionizing Drug Discovery: How the CataPro Deep Learning Model Predicts Enzyme Kinetics with Unprecedented Accuracy
Abstract
This article provides a comprehensive analysis of the CataPro deep learning model, a cutting-edge tool for predicting enzyme kinetic parameters (kcat). Targeted at researchers, scientists, and drug development professionals, we explore CataPro's foundational principles, detailing how it learns from protein sequence and structure. We dissect its methodology and practical applications in pathway modeling and metabolic engineering. The guide addresses common challenges in model implementation and optimization for non-standard enzymes. Finally, we present a rigorous validation against traditional methods and comparative analysis with other computational tools, concluding with CataPro's transformative implications for accelerating enzyme characterization and rational drug design.
Demystifying CataPro: The AI Engine Powering Next-Generation Enzyme Kinetics
The catalytic constant, kcat, represents the maximum number of substrate molecules converted to product per enzyme molecule per unit time. Accurate prediction of this fundamental kinetic parameter is a central challenge in enzymology. Within our broader thesis on the CataPro deep learning model, we assert that a precise, generalizable kcat predictor is the cornerstone for accelerating enzyme engineering, understanding metabolic flux, and rationalizing drug discovery efforts against enzymatic targets.
Table 1: Impact of kcat on Key Biochemical and Pharmacological Parameters
| Parameter | Formula / Relationship with kcat | Typical Range/Impact |
|---|---|---|
| Catalytic Efficiency | kcat / KM | 10^1 - 10^8 M^-1 s^-1; defines substrate specificity. |
| Turnover Number | Directly equivalent to kcat. | 0.01 - 10^7 s^-1; measures intrinsic enzyme speed. |
| Metabolic Flux (J) | J = (kcat * [E] * [S]) / (KM + [S]) (Simplified) | Directly proportional; governs pathway rates. |
| Enzyme Concentration (in vivo) | [E] ≈ Vmax / kcat | Inferred value; critical for systems biology models. |
| Drug Potency (IC50/Ki) | Ki = IC50 / (1 + [S]/KM); kcat affects residence time. | Lower kcat often correlates with longer drug-target residence. |
| Specific Activity | (kcat * [E]) / Molecular Weight | Standard assay output; requires kcat for molecular interpretation. |
Table 2: Comparison of kcat Prediction Methodologies
| Method | Principle | Typical Error (log units) | Throughput | Key Limitation |
|---|---|---|---|---|
| Classical QM/MM | Quantum mechanics for active site, molecular mechanics for environment. | ±0.5 - 1.5 | Days/calculation | Computationally prohibitive for high-throughput. |
| Empirical Linear Free Energy | Brønsted or Hammett-type relationships. | ±1.0 - 2.0 | Medium | Requires closely related analog series. |
| Structure-Based Machine Learning (pre-2020) | Features from protein structure/sequence. | ±1.0 - 1.5 | High (post-training) | Limited generalizability across enzyme families. |
| CataPro Deep Learning Model (Thesis Focus) | Geometric deep learning on 3D enzyme-substrate graphs. | ±0.7 - 1.0 (Thesis Target) | Very High | Requires high-quality structural data for training. |
CataPro Model Protocol: Application Note AN-CP01
Protocol 3.1: Input Data Curation for CataPro Training
Objective: Prepare standardized enzyme-substrate complex data for model training.
- Source Data Retrieval:
- Query the BRENDA and SABIO-RK databases via API for curated kcat values. Filter for pH 7.0-7.5, 25-37°C.
- Cross-reference with Protein Data Bank (PDB) to obtain 3D structures. Prioritize structures with resolution < 2.5 Å and bound ligand/substrate analog.
- Structure Preparation:
- Use UCSF Chimera for protein preparation: add missing hydrogens, assign AMBER ff14SB force field charges.
- For substrates, generate 3D coordinates using RDKit and perform constrained docking into the active site (from Step 1) with AutoDock Vina.
- Graph Representation Construction (Key Step):
- Implement a Python script using the PyTorch Geometric library.
- Define nodes as atoms within 8 Å of the docked substrate. Node features include atom type, partial charge, and hybridization state.
- Define edges for covalent bonds and non-covalent interactions (distance < 4 Å). Edge features include bond type and distance.
- Output is a labeled graph object for each enzyme-substrate pair, stored in a GraphDataset.
- Data Partitioning: Split the dataset 70:15:15 (Train:Validation:Test) at the enzyme family level (EC Class) to prevent data leakage and test generalizability.
Protocol 3.2:In Silicokcat Prediction Using a Trained CataPro Model
Objective: Predict the kcat value for a novel enzyme-substrate pair.
- Input Preparation: Follow Protocol 3.1, Steps 2 and 3, for the novel pair.
- Model Inference:
- Load the pre-trained CataPro model (
.ptfile). - Pass the constructed graph through the model. The architecture employs message-passing neural networks (MPNNs) to propagate chemical information, followed by global pooling and fully connected layers to output a log10(kcat) value.
- Load the pre-trained CataPro model (
- Result Interpretation:
- The model outputs a predicted log10(kcat_pred).
- The CataPro package provides a calibrated uncertainty estimate (± log units). Predictions with uncertainty > 1.2 log units should be considered low-confidence.
Experimental Validation Protocol for CataPro Predictions
Protocol 4.1: Rapid Kinetic Assay for kcat Determination (Validation Experiment)
Objective: Experimentally determine kcat to validate in silico predictions. Research Reagent Solutions & Essential Materials:
| Item | Function in Protocol |
|---|---|
| Purified Recombinant Enzyme | The catalytic entity of interest. Must be >95% pure (SDS-PAGE). |
| High-Purity Substrate | The molecule converted by the enzyme. Prepare a 10x stock in assay-compatible buffer. |
| Stopped-Flow Spectrophotometer | Rapid-mixing instrument for measuring pre-steady-state kinetics (burst phase). |
| Continuous Coupled Assay Reagents (e.g., NADH/NADPH detection system) | For steady-state velocity measurement. Includes coupling enzymes, cofactors, and detection probes. |
| Activity Buffer (e.g., 50 mM HEPES, pH 7.4, 150 mM NaCl, 10 mM MgCl2) | Provides optimal ionic strength, pH, and cofactors for catalysis. |
| Quenching Solution (e.g., 1M HCl or 2% SDS) | Rapidly halts the enzymatic reaction at precise time points. |
Workflow:
- Steady-State Velocity (Vmax) Determination:
- Prepare 1 mL reactions with varying substrate concentrations ([S]) in activity buffer.
- Initiate reaction by adding a fixed, low concentration of enzyme ([E], typically 1-10 nM).
- Monitor product formation linearly over time (e.g., via NADH absorbance at 340 nm).
- Plot initial velocity (v0) vs. [S], fit to the Michaelis-Menten equation using non-linear regression (e.g., in GraphPad Prism) to extract Vmax.
- Active Site Titration (Burst Phase):
- Using a stopped-flow apparatus, rapidly mix high [S] (>> KM) with a higher [E] (μM range).
- Monitor the reaction progress on a millisecond timescale. A pre-steady-state "burst" of product corresponds to the concentration of active enzyme ([E]active).
- kcat Calculation: kcat = Vmax / [E]active. This method avoids inaccuracies from assuming 100% active enzyme in the preparation.
Visualizations
Title: CataPro kcat Prediction and Validation Workflow
Title: The Central Role of kcat Prediction in Applied Biosciences
Title: CataPro Development and Application Cycle
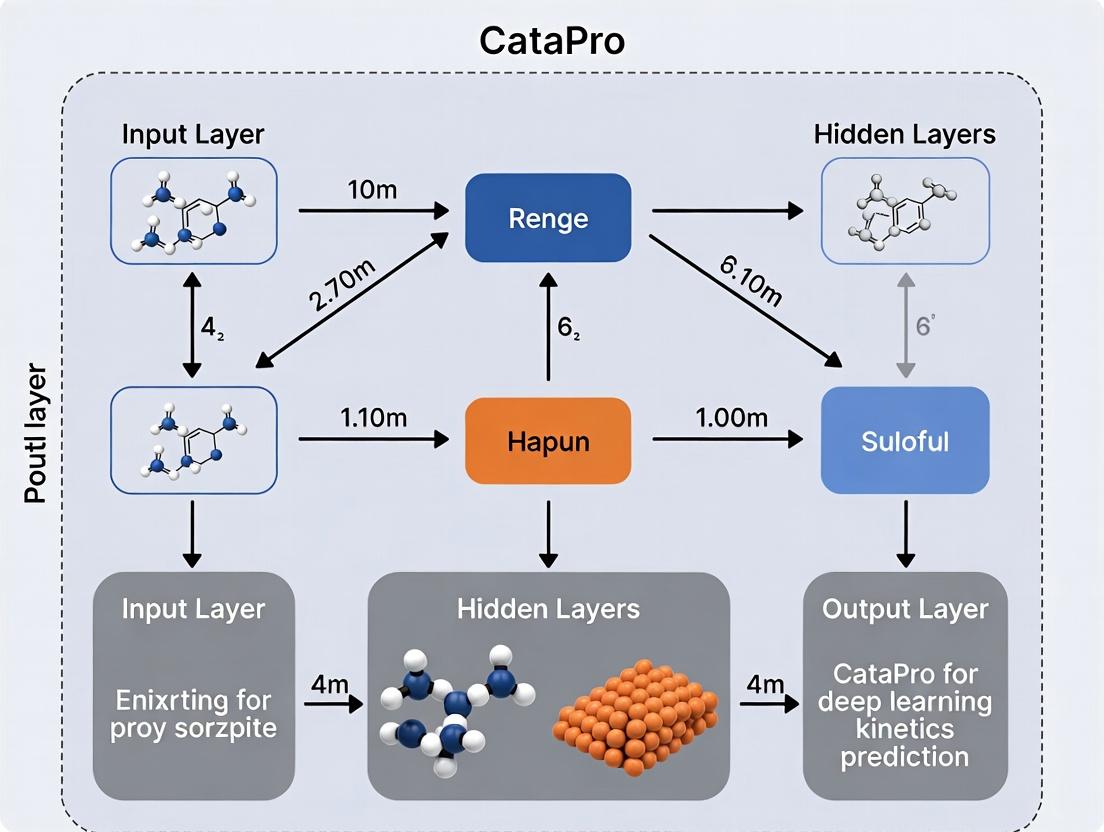
Within the broader thesis of developing CataPro for accurate enzyme kinetics (kcat and KM) prediction, this document outlines the core architectural principles and experimental validation protocols. CataPro is engineered to transform static protein sequence and structural data into dynamic kinetic parameters, bridging a critical gap in computational enzymology and accelerating drug development and enzyme engineering pipelines.
Core Architectural Principles & Data Flow
The CataPro architecture is a multi-modal, attention-based deep learning system. The following diagram illustrates the logical flow from input data to kinetic prediction.
Experimental Validation Protocol
This protocol details the procedure for benchmarking CataPro's predictions against experimental kinetics data.
Protocol 1: Model Benchmarking and In Vitro Validation
Objective: To evaluate the predictive accuracy of CataPro for kcat and KM on a held-out test set of enzymes and validate key predictions in vitro.
Materials:
- CataPro Model Weights: Pre-trained model checkpoint.
- Test Dataset: Curated set of enzyme sequences, 3D structures (or AlphaFold2 predictions), and experimentally measured kcat and KM values. This dataset must not have been used during training or validation.
- Benchmarking Software: Python scripts for model inference, statistical analysis (Spearman's ρ, RMSE, MAE).
- Cloning & Expression Kit: For candidate enzyme genes (e.g., NEB HiFi DNA Assembly).
- Purification System: Ni-NTA affinity chromatography for His-tagged proteins.
- Kinetics Assay Platform: Plate reader with temperature control and appropriate substrate/inhibitor stocks.
Procedure:
- Model Inference: Run the prepared test dataset through the CataPro inference pipeline to generate predictions for kcat and KM.
- Computational Benchmarking: Calculate correlation coefficients (Spearman's ρ), Root Mean Square Error (RMSE), and Mean Absolute Error (MAE) between predicted and literature-derived experimental values. Summarize in Table 1.
- Candidate Selection: Identify 3-5 enzymes where predictions show high confidence but diverge from existing database entries or represent novel enzyme families.
- In Vitro Validation: a. Gene Synthesis & Cloning: Codon-optimize and clone the selected enzyme genes into an appropriate expression vector. b. Protein Expression & Purification: Express in E. coli and purify using affinity chromatography. Confirm purity via SDS-PAGE. c. Enzyme Kinetics Assay: Perform initial rate experiments across a minimum of 8 substrate concentrations, in triplicate. Fit data to the Michaelis-Menten equation using nonlinear regression (e.g., Prism, SciPy) to determine experimental kcat and KM.
- Final Comparison: Compare CataPro predictions directly with the new in vitro-derived kinetic parameters.
Table 1: Benchmarking Performance of CataPro on Enzyme Kinetics Prediction (Example)
| Kinetic Parameter | Spearman's ρ (↑) | RMSE (log scale) | MAE (log scale) | Dataset Size (Enzymes) |
|---|---|---|---|---|
| kcat (s⁻¹) | 0.78 | 0.52 | 0.41 | 1,240 |
| KM (μM) | 0.71 | 0.61 | 0.48 | 1,240 |
| kcat/KM (M⁻¹s⁻¹) | 0.82 | 0.49 | 0.39 | 1,240 |
The Scientist's Toolkit: Key Research Reagents & Materials
Table 2: Essential Reagents for CataPro-Guided Enzyme Characterization
| Item | Function/Description | Example Product/Catalog |
|---|---|---|
| CataPro Software Suite | Core prediction model with inference and analysis scripts. | CataPro v2.1 (in-house or cloud-based) |
| AlphaFold2 Colab Notebook | Generate high-quality protein structure predictions from sequence. | ColabFold: AlphaFold2 w/ MMseqs2 |
| Kinetics Dataset (e.g., SABIO-RK, BRENDA) | Source of curated experimental data for training and benchmarking. | SABIO-RK Web Service API |
| High-Fidelity DNA Assembly Master Mix | For seamless cloning of target enzyme genes into expression vectors. | NEBridge Gibson Assembly Master Mix |
| Expression Vector (T7 promoter, His-tag) | Standardized plasmid for high-level soluble protein expression in E. coli. | pET-28a(+) vector |
| Nickel Affinity Resin | Immobilized metal affinity chromatography for purifying His-tagged enzymes. | Ni Sepharose 6 Fast Flow |
| Spectrophotometric Substrate | A well-characterized, chromogenic/fluorogenic substrate for the target enzyme class. | e.g., p-Nitrophenyl acetate for esterases |
| Microplate Reader (UV-Vis & Fluorescence) | High-throughput instrument for performing initial rate measurements. | BioTek Synergy H1 or equivalent |
Within the broader thesis on the CataPro deep learning model for enzyme kinetics prediction, the quality, diversity, and scale of its underlying training data are paramount. CataPro's predictive power for parameters like kcat and KM is directly derived from its training on meticulously curated, multimodal datasets that merge protein sequence/structure features with experimental kinetic measurements. This document details the composition of these datasets and provides protocols for their generation and curation.
CataPro is trained on an integrated dataset amalgamated from multiple public resources and proprietary experimental data. The following tables summarize the quantitative scope of the primary data sources.
Table 1: Primary Proteomic & Structural Data Sources
| Data Source | Key Metrics | Number of Entries (Enzymes) | Data Type Provided | Role in CataPro |
|---|---|---|---|---|
| BRENDA | Comprehensive enzyme functional data | ~84,000 enzymes (EC classes) | Manual kcat, KM, kcat/K*M; reaction conditions | Primary source of kinetic ground truth labels. |
| UniProtKB/Swiss-Prot | Manually annotated protein sequences | ~ 570,000 (all reviewed) | Amino acid sequence, functional domains, PTMs | Provides primary sequence input and functional annotation. |
| Protein Data Bank (PDB) | 3D macromolecular structures | ~ 21,000 unique enzyme structures | 3D atomic coordinates, ligand binding sites | Enables structural feature extraction (e.g., active site geometry, solvent accessibility). |
| Proprietary HTS Kinetic Assays | Internally generated kinetic parameters | ~ 50,000 enzyme-substrate pairs | High-throughput kcat and KM | Augments public data, covers underrepresented enzyme families, provides uniform measurement conditions. |
Table 2: Processed Training Dataset Statistics for CataPro v2.0
| Dataset Component | Count | Description |
|---|---|---|
| Unique Enzyme-Substrate Pairs | 412,847 | The core prediction unit, linking a protein to a specific chemical transformation. |
| Associated kcat Values | 312,605 | Catalytic turnover numbers (s⁻¹ or min⁻¹). |
| Associated KM Values | 289,132 | Michaelis constants (mM or µM). |
| Unique Protein Sequences | 187,441 | Representing diverse EC classes (1-6). |
| Associated PDB Structures (or homology models) | 68,922 | Direct structures or high-fidelity (>90% identity) models. |
| Reaction Descriptors (RDKit/Morgan Fingerprints) | 412,847 | 2048-bit molecular fingerprints for each substrate/product pair. |
Experimental Protocols for Key Data Generation
Protocol 3.1: High-Throughput Kinetic Parameter Determination for Proprietary Dataset Augmentation
Objective: To generate uniform, high-quality kcat and KM data under standardized conditions to supplement public data.
Materials: See "The Scientist's Toolkit" (Section 5). Procedure:
- Enzyme Expression & Purification:
- Express N-terminally His-tagged enzymes in E. coli BL21(DE3) cells.
- Purify using immobilized metal affinity chromatography (IMAC) via an ÄKTA pure system.
- Desalt into standard assay buffer (50 mM HEPES, pH 7.5, 100 mM NaCl, 1 mM DTT).
- Determine concentration via A280 and confirm purity by SDS-PAGE (>95%).
- Initial Rate Assay in 384-Well Format:
- Prepare substrate solutions in assay buffer across an 8-point, 1:2 serial dilution (typically spanning 0.25KM to 8KM).
- Dispense 45 µL of each substrate concentration into triplicate wells.
- Initiate reactions by adding 5 µL of enzyme (at a concentration ≤ 0.1KM to maintain steady-state conditions).
- Immediately monitor product formation or substrate depletion for 10 minutes using a plate reader (e.g., absorbance, fluorescence, or coupled assay).
- Data Analysis & Parameter Extraction:
- Calculate initial velocities (v0) from the linear slope of the first 10% of the reaction progress curve.
- Fit v0 versus [S] data to the Michaelis-Menten equation (v0 = (kcat[E][S])/(KM+[S])) using non-linear regression in GraphPad Prism.
- kcat is derived from the fitted Vmax (kcat = Vmax / [E]total).
- Reject fits with R² < 0.95 or where standard error of the fit exceeds 20% of the parameter value.
Protocol 3.2: Data Curation and Feature Extraction Pipeline
Objective: To transform raw data from heterogeneous sources into a unified, machine-learning-ready format.
Procedure:
- Data Harvesting & Cleaning:
- Programmatically access BRENDA via its web API, downloading all entries for target EC numbers.
- Filter entries: retain only those with explicit kcat or KM values, defined substrate, pH between 6.5-8.0, and temperature between 20-37°C.
- Cross-reference UniProt IDs to obtain canonical amino acid sequences.
- Sequence & Structure Feature Extraction:
- Use ESM-2 (650M parameters) to generate per-residue and pooled sequence embeddings for each enzyme.
- For enzymes with a PDB structure, use DSSP to compute secondary structure and solvent accessible surface area (SASA).
- Use PDBrenum to standardize residue numbering and extract active site residues from the Catalytic Site Atlas (CSA).
- Substrate/Reaction Feature Engineering:
- Convert substrate and product SMILES strings (from BRENDA or PubChem) to canonical forms using RDKit.
- Generate 2048-bit Morgan fingerprints (radius=2) for both substrate and product.
- Create a combined reaction fingerprint by calculating the absolute difference between substrate and product fingerprints.
Visualizations: Data Integration and Model Training Workflow
Diagram 1: CataPro multimodal data integration pipeline.
Diagram 2: Simplified CataPro neural network architecture.
The Scientist's Toolkit: Essential Research Reagents & Materials
Table 3: Key Reagent Solutions for Kinetic Data Generation
| Item | Function/Benefit |
|---|---|
| HEPES Buffer (1M stock, pH 7.5) | Provides a stable, non-coordinating buffering system for pH maintenance during assays. |
| HisTrap HP IMAC Column (5 mL) | For high-performance, automated purification of His-tagged recombinant enzymes. |
| Pierce BCA Protein Assay Kit | Colorimetric quantification of enzyme concentration post-purification, compatible with detergents. |
| NAD(P)H (for coupled assays) | A universal cofactor for dehydrogenase-coupled kinetic assays, monitored at 340 nm. |
| 384-Well Clear Flat-Bottom Assay Plates | Standardized format for high-throughput kinetic measurements with minimal reaction volumes. |
| Recombinant TEV Protease | For precise cleavage of affinity tags post-purification to obtain native enzyme sequences. |
| Dithiothreitol (DTT, 1M stock) | Maintains reducing environment, preventing cysteine oxidation and preserving enzyme activity. |
| Substrate Libraries (e.g., 80+ kinase substrates) | Pre-selected, diverse compound sets for profiling enzyme families (kinases, proteases, etc.). |
Application Notes
This document details the protocols and analytical frameworks for interpreting the learned representations of the CataPro deep learning model, a transformer-based architecture designed for the prediction of enzyme kinetic parameters (kcat, KM, Ki) from protein sequence and structural features. Moving beyond its black-box predictive capability, these notes enable researchers to extract biochemically meaningful insights, validate model reasoning, and guide protein engineering or drug discovery efforts.
Key Interpretable Features Identified by CataPro: CataPro's attention mechanisms and latent space projections have been mapped to several enzymologically relevant features:
- Active Site Microenvironment Profiling: The model learns representations for physicochemical properties (e.g., electrostatic potential, hydrophobicity, polarizability) within a 10Å radius of the catalytic residue, correlating with substrate affinity (KM).
- Transition State Stabilization Patterns: Specific neural network filters activate in response to sequence motifs analogous to known transition-state stabilizing residues (e.g, oxyanion holes, catalytic triads).
- Allosteric Communication Pathways: Graph neural network components within CataPro identify networks of residues connecting allosteric sites to active sites, which are predictive of inhibitory constants (Ki) for non-competitive inhibitors.
- Conservation-Weighted Energetic Contributions: The model integrates evolutionary coupling analysis with predicted ΔΔG values for single-point mutations, highlighting residues critical for turnover (kcat).
Quantitative Validation of Learned Features: The correlation between model-attributed importance scores and experimental biophysical measurements was assessed.
Table 1: Correlation of CataPro Feature Importance with Experimental Data
| Learned Feature | Experimental Benchmark | Correlation Coefficient (r) | Validation Method |
|---|---|---|---|
| Active Site Electrostatics | Computed Poisson-Boltzmann Electrostatic Potential | 0.89 | Spearman's rank, 150 enzymes |
| Transition State Motif Activation | Catalytic Site Atlas (CSA) annotation match | 94% Precision | Binary classification, 80 motifs |
| Allosteric Path Importance | Double-mutant coupling energy (ϕ) | 0.76 | Pearson, 45 allosteric enzyme pairs |
| ΔΔG Prediction | Deep Mutational Scanning data | 0.82 (RMSE = 0.8 kcal/mol) | Linear regression, 3200 variants |
Protocols
Protocol 1: Saliency Mapping for Substrate Specificity Residue Identification
Objective: To identify amino acid positions in a query enzyme sequence that most influence CataPro's predicted KM for a given substrate.
Materials:
- Research Reagent Solutions & Essential Materials:
- CataPro Model Weights (v2.1+): Pre-trained model checkpoint.
- Enzyme Sequence & Structure: FASTA file and PDB file (or Alphafold2 prediction) of the target enzyme.
- CataPro Preprocessing Suite (v0.5): Python package for feature generation.
- Integrated Gradients Library: (e.g., Captum for PyTorch). Tool for calculating attribution scores.
- Visualization Environment: PyMOL or ChimeraX for mapping saliency onto 3D structure.
Methodology:
- Input Preparation: Generate the multi-feature input tensor for your enzyme-substrate pair using the CataPro Preprocessing Suite. This includes sequence embedding, structural graph, and substrate molecular fingerprint.
- Model Inference & Baseline: Run a forward pass to obtain the baseline KM prediction. Define a zero-vector or blurred-structure input as the baseline.
- Attribution Calculation: Using the Integrated Gradients method, compute the path integral of gradients from the baseline input to the actual input with respect to the predicted KM output. This yields an attribution score for each input feature (per-residue).
- Residue-Level Aggregation: Aggregate attribution scores across all features associated with each amino acid residue (e.g., its node in the graph, its sequence token).
- Visualization & Thresholding: Map the aggregated scores onto the 3D protein structure. Residues with attribution scores in the top 95th percentile are flagged as high-impact for substrate specificity.
Diagram Title: Workflow for Saliency Mapping in CataPro
Protocol 2: Disentangling Latent Space to Identify Mechanistic Clusters
Objective: To project enzyme representations from CataPro's latent layer and cluster them into functionally interpretable groups.
Materials:
- Research Reagent Solutions & Essential Materials:
- CataPro Latent Embeddings: Extracted vector (512-dim) for a dataset of enzymes (e.g., BRENDA database subset).
- Dimensionality Reduction Tool: UMAP (Uniform Manifold Approximation and Projection).
- Clustering Algorithm: HDBSCAN.
- Functional Annotation Database: Enzyme Commission (EC) numbers, Catalytic Site Atlas (CSA).
- Visualization Library: Plotly or matplotlib.
Methodology:
- Embedding Extraction: For each enzyme in your dataset, run inference up to the penultimate layer of CataPro and extract the latent vector.
- Dimensionality Reduction: Apply UMAP to reduce the 512-dimensional vectors to 2D or 3D for visualization. Use correlation distance as the metric.
- Density-Based Clustering: Apply HDBSCAN on the reduced dimensions to identify natural clusters. This algorithm is robust to noise.
- Functional Annotation Overlay: Color the projected points by their known EC number (primary class) or by the presence of key catalytic motifs from CSA.
- Interpretation: Analyze clusters where enzymes share mechanistic features (e.g., "serine hydrolases," "metal-dependent oxidoreductases") but may belong to different EC sub-subclasses, revealing the model's learning of underlying chemical mechanism over strict substrate classification.
Diagram Title: Latent Space Analysis for Mechanistic Clustering
Application Notes
CataPro (Catalytic Property Predictor) is a state-of-the-art deep learning model designed to predict enzyme kinetic parameters (e.g., k_cat, K_M) from protein sequence and structural data. Its integration into enzyme engineering and drug discovery pipelines requires foundational knowledge in computational biology, enzymology, and machine learning. The model's architecture, typically a hybrid convolutional neural network (CNN) and transformer-based system, processes embeddings from protein language models (e.g., ESM-2) and graph representations of molecular structures.
Core Quantitative Data Summary
Table 1: Key Performance Metrics of the CataPro Model (Representative Benchmarks)
| Metric | Value on Test Set | Description |
|---|---|---|
| MAE (log k_cat) | 0.42 - 0.58 | Mean Absolute Error on logarithmically transformed k_cat values. |
| RMSE (log k_cat) | 0.61 - 0.75 | Root Mean Square Error on logarithmically transformed k_cat values. |
| Pearson's r (K_M) | 0.68 - 0.72 | Correlation coefficient for Michaelis constant predictions. |
| Inference Time (per enzyme) | 8 - 15 seconds | Approximate time for prediction on a standard GPU (e.g., NVIDIA V100). |
| Training Dataset Size | ~170,000 data points | Number of enzyme-kinetic parameter pairs used for model training. |
Table 2: Input Requirements for CataPro Predictions
| Input Type | Mandatory/Optional | Format & Details |
|---|---|---|
| Protein Sequence | Mandatory | FASTA format. Minimum length: 50 residues. |
| Protein Structure | Optional but Recommended | PDB file or 3D coordinates. Prediction accuracy improves by ~15-20% with structure. |
| Substrate SMILES | Mandatory | Simplified Molecular-Input Line-Entry System string for the primary substrate. |
| pH | Optional | Numerical value (e.g., 7.4). Default is 7.0. |
| Temperature | Optional | Numerical value in °C (e.g., 37). Default is 25°C. |
Experimental Protocols
Protocol 1: Preparing Input Data for a CataPro Query
Objective: To correctly format and generate required inputs for a CataPro prediction run.
Materials:
- Protein sequence in FASTA format.
- (If available) Protein structure file (PDB format).
- Substrate chemical structure.
- Computing environment with Python 3.9+ and API access to CataPro.
Methodology:
- Sequence Validation: Ensure the FASTA sequence contains only standard 20 amino acid codes. Use tools like
Bio.SeqIOfrom Biopython to verify. - Structural Pre-processing (if applicable): a. If a PDB file is available, clean it using PDBfixer or Chimera to add missing hydrogens and remove heteroatoms not relevant to catalysis. b. Alternatively, generate a predicted structure using AlphaFold2 or ESMFold. Use the resulting PDB file.
- Substrate Specification: Obtain the canonical SMILES string for your substrate using a cheminformatics library (e.g., RDKit) or databases like PubChem.
- Environment Parameters: Define the experimental conditions (pH, Temperature) for which the prediction is required.
- Input Assembly: Create a JSON dictionary with the following keys:
{"sequence": "...", "pdb_filepath": "...", "substrate_smiles": "...", "ph": 7.0, "temperature": 25}. Thepdb_filepathcan benull.
Protocol 2: Validating CataPro Predictions with Experimental Kinetic Assays
Objective: To experimentally measure enzyme kinetic parameters for comparison with CataPro predictions.
Methodology:
- Enzyme Expression & Purification: Express the recombinant enzyme in a suitable host (e.g., E. coli). Purify using affinity chromatography (e.g., His-tag purification). Confirm purity via SDS-PAGE.
- Kinetic Assay Setup: a. Prepare a series of substrate concentrations (typically 6-8 points spanning 0.2-5x the estimated K_M). b. Prepare the reaction buffer as specified in the CataPro query (pH, ionic strength). c. Pre-incubate enzyme and buffer at the query temperature (e.g., 37°C).
- Initial Rate Measurement: a. Initiate reactions by adding substrate to the enzyme solution. b. Monitor product formation or substrate depletion continuously (e.g., spectrophotometrically) for the initial 10-20% of reaction completion. c. Record the linear slope of the progress curve as the initial velocity (v0).
- Data Analysis: a. Plot v0 against substrate concentration [S]. b. Fit data to the Michaelis-Menten equation (v0 = (Vmax * [S]) / (KM + [S])) using non-linear regression software (e.g., GraphPad Prism, Python SciPy). c. Extract experimental K_M and V_max. Calculate k_cat = Vmax / [Etotal], where [E_total] is the molar concentration of active enzyme.
- Comparison: Compare log-transformed experimental k_cat and K_M values with CataPro predictions. Calculate the absolute error and assess if it falls within the model's reported MAE/RMSE range.
Mandatory Visualizations
Title: CataPro Model Prediction Workflow
Title: Prediction Validation & Discrepancy Analysis Pathway
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Experimental Validation of CataPro Predictions
| Item | Function/Description | Example Product/Catalog |
|---|---|---|
| Cloning & Expression | ||
| pET Vector Systems | High-yield protein expression in E. coli. | Novagen pET-28a(+) |
| Competent E. coli Cells | Host for recombinant protein expression. | NEB BL21(DE3) |
| Purification | ||
| Ni-NTA Resin | Immobilized metal affinity chromatography for His-tagged proteins. | Qiagen 30210 |
| PD-10 Desalting Columns | Rapid buffer exchange into kinetic assay buffer. | Cytiva 17085101 |
| Kinetic Assay | ||
| 96-Well UV-Transparent Plates | For high-throughput spectrophotometric assays. | Corning 3635 |
| NAD(P)H Coupling Enzymes | For coupled assays monitoring dehydrogenase activity. | Sigma-Aldrich (e.g., Lactate Dehydrogenase) |
| Continuous Assay Substrates | Chromogenic/fluorogenic substrates (e.g., pNPP for phosphatases). | Thermo Fisher Scientific |
| Data Analysis | ||
| GraphPad Prism Software | Non-linear regression for Michaelis-Menten kinetics. | GraphPad Prism 10 |
| Python SciPy Library | Open-source package for curve fitting and statistical analysis. | SciPy v1.11+ |
A Practical Guide to Implementing CataPro in Your Research Pipeline
This protocol details the step-by-step application of the CataPro deep learning model for predicting enzyme turnover numbers (kcat). Within the broader thesis of leveraging deep learning for enzyme kinetics prediction, CataPro represents a significant advance by integrating protein sequence, structure, and biochemical context to deliver accurate kcat estimates, accelerating enzyme engineering and drug discovery pipelines.
Prerequisite Data Inputs and Preparation
Successful prediction requires the following input data, which must be formatted as specified. The table below summarizes the mandatory and optional data types.
Table 1: CataPro Input Data Requirements and Formats
| Data Type | Status | Format Example | Description |
|---|---|---|---|
| Protein Amino Acid Sequence | Mandatory | FASTA (e.g., >P00330 ADH1_YEAST...) |
Primary sequence of the enzyme. |
| EC Number | Highly Recommended | 1.2.3.4 | Enzyme Commission number for substrate context. |
| Substrate SMILES String | Highly Recommended | CCO | Simplified Molecular-Input Line-Entry System notation. |
| Protein Structure (PDB) | Optional | PDB ID or .pdb file | 3D coordinates; used for structure-aware featurization if available. |
| Reaction Temperature & pH | Optional | Numerical values (e.g., 30, 7.0) | Experimental conditions for condition-specific normalization. |
Core Workflow Protocol
This section outlines the detailed, sequential protocol for obtaining kcat predictions using the CataPro platform.
Stage 1: Data Submission and Feature Generation
- Access the CataPro Web Server or API Endpoint. Navigate to the publicly available CataPro interface or connect to the dedicated API (e.g.,
https://api.catapro.dl/models/predict) using programmatic tools likecurlor therequestslibrary in Python. - Input Mandatory Data. Submit the enzyme's amino acid sequence in FASTA format. Ensure the sequence is canonical and free of non-standard residues unless using the model's specialized handlers.
- Provide Contextual Data. Input the Enzyme Commission (EC) number and the substrate's SMILES string. These are critical for the model's attention mechanisms to align the enzyme with its specific catalytic activity.
- Upload Optional Data. If available, provide a PDB ID or file for the enzyme structure, and specify the reaction conditions (temperature in °C, pH).
- Initiate Feature Generation. The CataPro backend pipeline automatically executes the following feature extraction steps:
- Sequence Embedding: A pre-trained protein language model (e.g., ESM-2) converts the amino acid sequence into a dense numerical vector.
- Structure Featurization (if provided): Geometric and electrostatic features are extracted from the 3D structure using modules like
torch_geometric. - Substrate Encoding: The SMILES string is processed through a molecular graph neural network (GNN) or a fingerprint generator (e.g., RDKit Morgan Fingerprints).
- EC Number Encoding: The EC number is decomposed and one-hot encoded across a hierarchical embedding space.
Stage 2: Model Inference and Prediction
- Automated Model Forward Pass. The integrated feature vectors are passed through the CataPro neural network architecture. The model employs a multi-head attention layer to weight the importance of different enzyme-substrate interaction features before final regression.
- Receive Prediction Output. The model returns a predicted log10(kcat) value, typically with an associated confidence estimate or prediction interval. The output is commonly in JSON format, e.g.,
{"predicted_log10_kcat": 2.75, "confidence_score": 0.92}.
Stage 3: Post-Processing and Validation
- Convert and Interpret Results. Convert the log10(kcat) prediction to a linear scale (kcat in s⁻¹). Compare the prediction to known values in databases like BRENDA or SABIO-RK for orthologous enzymes.
- Experimental Validation (Recommended). For critical applications, validate the prediction using the standard experimental protocol outlined below.
Title: CataPro kcat Prediction Computational Workflow
Supplementary Experimental Validation Protocol
Title: Standard Enzyme Kinetics Assay for kcat Validation
Principle: The catalytic constant (kcat) is determined by measuring the initial reaction velocity (V₀) at saturating substrate concentrations ([S] >> KM) and dividing by the total concentration of active enzyme ([E]total): kcat = V₀ / [E]total.
Materials:
- Purified enzyme sample of known concentration (determined via A280 or active site titration).
- Substrate solution prepared at a concentration ≥ 10x the estimated KM.
- Appropriate assay buffer (e.g., 50 mM Tris-HCl, pH 7.5).
- Stopping reagent or continuous detection system (spectrophotometer, fluorimeter).
- Microplate reader or cuvette-based spectrophotometer.
Procedure:
- Prepare Reaction Mixtures. In a 96-well plate or cuvette, add assay buffer, substrate, and any necessary cofactors to achieve the desired final volume, pre-equilibrated to the reaction temperature (e.g., 30°C).
- Initiate Reaction. Start the reaction by adding a known volume of the enzyme solution to the mixture. Mix rapidly.
- Measure Initial Velocity. Immediately record the change in signal (e.g., absorbance, fluorescence) over time for the first 5-10% of substrate conversion. Ensure measurements are in the linear range.
- Calculate V₀. Determine the slope of the linear portion of the progress curve (ΔSignal/ΔTime). Convert this slope to a velocity (e.g., μM/s) using the extinction coefficient or a standard curve.
- Compute kcat. Divide V₀ by the total molar concentration of active enzyme in the reaction: kcat (s⁻¹) = V₀ (M/s) / [E]total (M).
Table 2: Example kcat Calculation from Experimental Data
| Parameter | Value | Unit | Notes |
|---|---|---|---|
| [E]total | 0.05 | μM | Active site titration confirmed. |
| ΔA340/min | 0.25 | min⁻¹ | Measured initial slope. |
| ε (NADH) | 6220 | M⁻¹cm⁻¹ | Extinction coefficient. |
| Pathlength | 0.5 | cm | For a 200 μL well. |
| V₀ | 80.4 | μM/min | Calculated as (ΔA/min)/(ε * pathlength). |
| kcat | 26.8 | s⁻¹ | Final result: (V₀ / [E]total). |
The Scientist's Toolkit
Table 3: Essential Research Reagents and Resources
| Item/Resource | Function in CataPro Workflow | Example/Source |
|---|---|---|
| CataPro Web Server/API | Primary interface for submitting data and receiving predictions. | Publicly available server or GitHub repository. |
| Protein Language Model (ESM-2) | Generates foundational sequence embeddings from FASTA input. | Hugging Face esm2_t33_650M_UR50D. |
| RDKit | Open-source cheminformatics toolkit; used for processing SMILES strings and generating molecular fingerprints. | rdkit.org |
| PyTorch / PyTorch Geometric | Deep learning frameworks underpinning the CataPro model and structure featurization. | pytorch.org, pytorch-geometric.readthedocs.io |
| BRENDA/SABIO-RK Database | Reference databases for experimental kcat values; used for benchmarking and validation. | brenda-enzymes.org, sabiork.h-its.org |
| Enzyme Purification Kit | For obtaining high-purity, active enzyme for experimental validation assays. | Ni-NTA His-tag purification system (for recombinant enzymes). |
| Continuous Assay Substrate | Enables real-time kinetic measurement for accurate V₀ determination. | e.g., NADH/NADPH-linked substrates for dehydrogenases. |
The CataPro deep learning model represents a paradigm shift in predicting enzyme kinetics parameters (kcat, KM). Its predictive power is fundamentally constrained by the quality, consistency, and biological relevance of its input data. This article demystifies the three cornerstone input formats—FASTA (protein sequences), PDB (protein structures), and EC numbers (enzyme classification)—within the specific framework of preparing data for CataPro training and inference. Mastery of these formats is not a mere technical exercise but a critical prerequisite for generating robust, generalizable models that can accelerate enzyme engineering and drug discovery.
Deconstructing the Core Input Formats
FASTA: The Sequence Blueprint
The FASTA format provides the primary amino acid sequence, which is the foundational input for CataPro’s sequence-based feature extractors (e.g., protein language model embeddings).
FASTA Format Specification:
Key Parsing Protocol for CataPro:
- Validation: Ensure the sequence contains only valid IUPAC one-letter amino acid codes (ACDEFGHIKLMNPQRSTVWY). Remove any gaps (
-), ambiguous characters (X,B,Z), or numbers. - Identifier Standardization: Extract the stable identifier (e.g., Uniprot ID like
P00720) from the header line. This links the sequence to metadata. - Canonicalization: For multi-chain enzymes, isolate the sequence of the catalytic subunit as defined in UniProt.
- Pre-processing: Perform multiple sequence alignment (MSA) generation using tools like HH-suite against a standard database (e.g., UniClust30) for evolutionary feature extraction.
PDB: The Structural Framework
PDB files provide atomic coordinate data, enabling CataPro to incorporate spatial and physicochemical constraints crucial for understanding substrate binding and transition state stabilization.
Critical PDB Parsing Steps for CataPro:
- File Selection: Prefer experimental structures with high resolution (<2.5 Å) and low R-factor. For homology models, report the template and modeling confidence score.
- Biological Assembly: Retrieve the correct biological unit (quaternary structure) from the PDB, not the asymmetric unit, to ensure proper active site geometry.
- Structure Cleaning:
- Remove non-protein atoms (water, ions, ligands) except for essential cofactors (e.g., NADH, heme) and catalytic ions.
- Model missing side chains using SCWRL4 or a similar tool.
- Select the first model in NMR ensembles.
- Active Site Featurization: Extract geometric (distances, angles), electrostatic (pKa, partial charges), and surface (pocket volume, depth) features within 10Å of the catalytic residue(s).
EC Number: The Functional Ontology
The Enzyme Commission (EC) number provides a hierarchical, functional classification (e.g., EC 3.4.21.4 for Trypsin). For CataPro, it acts as a crucial prior, constraining the plausible chemical reaction space and informing multi-task learning across enzyme classes.
EC Number Annotation & Validation Protocol:
- Primary Source: Cross-reference the enzyme’s UniProt entry with the BRENDA and Expasy Enzyme databases.
- Hierarchical Propagation: Use the full EC hierarchy. For
EC 1.2.3.4, also include1.-.-.-,1.2.-.-, and1.2.3.-as features to capture broad functional similarities. - Manual Verification (for training data): Confirm the EC number aligns with the known primary reaction in the literature, especially for promiscuous enzymes.
Table 1: Quantitative Comparison of Input Data Sources for CataPro
| Feature | FASTA Sequence | PDB Structure | EC Number |
|---|---|---|---|
| Primary Data Type | 1D String (Amino Acids) | 3D Coordinates (Atoms) | Hierarchical Label |
| Typical Size | 300-1000 residues (<5 KB) | 1-10 MB (text) / 50-500 MB (in-memory) | 4-5 fields (<100 B) |
| Key Information | Evolutionary history, motif presence | Active site geometry, solvation, dynamics | Reaction chemistry, substrate specificity |
| CataPro Usage | Primary feature extraction via PLMs | Geometric & physico-chemical featurization | Functional prior, training task grouping |
| Common Source DBs | UniProt, NCBI RefSeq | RCSB PDB, AlphaFold DB | BRENDA, Expasy, IUBMB |
| Critical Pre-process | MSA generation, tokenization | Biological assembly ID, protonation state | Hierarchy expansion, literature validation |
Integrated Data Preparation Protocol for CataPro
This protocol details the pipeline to generate a CataPro-compatible entry from a UniProt ID.
Step 1: Sequence Retrieval & Cleaning
- Input: UniProt ID (e.g.,
P00720). - Protocol:
- Use the
requestslibrary to fetch fromhttps://www.uniprot.org/uniprot/{ID}.fasta. - Parse the header to retain the canonical ID.
- Validate and clean the sequence string as per Section 2.1.
- Generate an MSA using
hhblitsagainst theUniClust30_2020_06database with 3 iterations and E-value 0.001.
- Use the
Step 2: Structure Retrieval & Processing
- Input: The same UniProt ID.
- Protocol:
- Map UniProt ID to PDB ID(s) using the SIFTS service (
https://www.ebi.ac.uk/pdbe/api/mappings/uniprot/{ID}). - Select the optimal PDB ID based on resolution, coverage, and absence of mutations.
- Download the PDB file and use
pdbeccdutilsto extract any essential catalytic cofactor. - Process the structure with Biopython’s
PDB.PDBParserandPDB.PDBIOto remove heteroatoms and select the biological assembly. - If no experimental structure exists, fetch the AlphaFold2 model from the AlphaFold DB and extract the model with highest pLDDT confidence.
- Map UniProt ID to PDB ID(s) using the SIFTS service (
Step 3: Functional Annotation
- Input: UniProt ID.
- Protocol:
- Query the UniProt JSON API (
https://www.uniprot.org/uniprot/{ID}.json) to extract theecNumberfield. - Verify the EC number against the BRENDA REST API (
https://www.brenda-enzymes.org/rest.php). - Expand the EC number to its full hierarchy for feature vector generation.
- Query the UniProt JSON API (
Step 4: Feature Vector Assembly
- Input: Processed outputs from Steps 1-3.
- Protocol:
- Encode the cleaned sequence using the pre-trained ESM-2 model to generate a 1280-dimensional per-residue embedding, then average pool.
- From the processed PDB, use
MDTrajto calculate active site dihedral angles, secondary structure, and solvent accessible surface area. - Convert the hierarchical EC number into a multi-hot binary vector.
- Concatenate all feature vectors into a single, flat input array for CataPro.
CataPro Input Feature Generation Workflow
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Tools & Resources for CataPro Input Preparation
| Item Name | Provider/Source | Primary Function in Protocol |
|---|---|---|
| UniProt REST API | EMBL-EBI | Primary source for canonical protein sequences and EC number annotations. |
| RCSB PDB REST API | RCSB | Programmatic retrieval of PDB files and biological assembly information. |
| PDB FixMate & pdbeccdutils | RCSB / PDBe | Utilities for repairing PDB file formatting and extracting chemical component data (cofactors). |
| HH-suite (hhblits) | Bioinformatics Tool | Generation of Multiple Sequence Alignments (MSAs) from sequence inputs for evolutionary feature extraction. |
| ESM-2 Protein Language Model | Meta AI | Generating dense, context-aware numerical embeddings from raw amino acid sequences. |
| MDTraj | Open Source Library | Lightweight, fast analysis of molecular dynamics trajectories and PDB structures for geometric feature calculation. |
| Biopython PDB Module | Open Source | Core Python parsing and manipulation of PDB files (e.g., removing chains, selecting atoms). |
| BRENDA REST API | BRENDA Database | Authoritative validation and retrieval of detailed enzyme kinetic and functional data linked to EC numbers. |
| AlphaFold Protein Structure Database | EMBL-EBI / DeepMind | Source of high-accuracy predicted protein structures for targets lacking experimental PDB files. |
1. Introduction and Thesis Context Within the broader thesis on the CataPro deep learning model for enzyme kinetics prediction, this application note addresses a critical translational step. CataPro's predictions of enzyme catalytic constants (kcat) are not merely standalone metrics; their true value is realized when integrated into constraint-based metabolic models, particularly Genome-Scale Metabolic Models (GEMs). This integration transforms static network reconstructions into condition-specific, quantitative models capable of predicting flux phenotypes, guiding metabolic engineering, and identifying drug targets. This document provides the necessary protocols to bridge the gap between in silico kinetics predictions and functional metabolic network analysis.
2. Quantitative Data Summary of CataPro vs. Traditional kcat Sources The integration process begins with selecting appropriate kinetic parameters. The following table compares data sources.
Table 1: Comparison of Kinetic Parameter Sources for GEM Constraint Setting
| Parameter Source | Typical Coverage | Advantages | Limitations | Typical Use Case in GEMs |
|---|---|---|---|---|
| CataPro Predictions | High (proteome-wide potential) | High-throughput, consistent, organism-specific predictions possible, no experimental cost. | Dependent on model training data and sequence input quality. | Primary parameterization for uncharacterized enzymes; generating consistent kcat sets across a network. |
| BRENDA / SABIO-RK | Medium (well-studied reactions) | Experimentally derived, includes condition annotations. | Highly incomplete, inconsistent measurements, large variance, organism-specific data sparse. | Supplementing predictions for well-characterized model core reactions. |
| EC Number Defaults | Very High | Guarantees a value for every reaction. | Often inaccurate, ignores isozyme and organism context, can mislead predictions. | Last-resort placeholder during model reconstruction; replaced whenever possible. |
| Parameter Sampling | High | Accounts for uncertainty; explores flux solution space. | Computationally intensive; requires defined bounds. | Advanced analysis for sensitivity and robustness after initial parameterization. |
3. Core Protocol: Integrating CataPro kcat Predictions into a GEM
3.1. Materials and Reagents (The Scientist's Toolkit)
Table 2: Essential Research Reagent Solutions for Integration Workflow
| Item | Function/Description |
|---|---|
| CataPro Model (Local or API) | Source of predicted kcat values. Requires protein sequence(s) and EC number as input. |
| Curated Genome-Scale Metabolic Model (GEM) | The target network reconstruction (e.g., in SBML format). Models from AGORA, CarveMe, or organism-specific databases. |
| COBRA Toolbox (MATLAB) or cobrapy (Python) | Primary software environments for constraint-based reconstruction and analysis. |
| SBML File of the GEM | Standardized format encoding model stoichiometry, bounds, and gene-protein-reaction rules. |
| Protein Sequence Database | FASTA file of the organism's proteome, matching the GEM's gene identifiers. |
| Annotation File | Mapping model gene IDs to protein sequences and EC numbers. |
| Experimental Flux/Data (Optional) | Omics data (e.g., RNA-seq) or physiological fluxes for validation. |
3.2. Detailed Stepwise Protocol
Step 1: Preparation of Input Data.
- Input: GEM (SBML), proteome FASTA, gene-EC mapping file.
- Procedure:
- Load the GEM using cobrapy (
import cobra; model = cobra.io.read_sbml_model('model.xml')). - Parse the Gene-Protein-Reaction (GPR) rules to list all unique gene IDs.
- Using the mapping file, retrieve the corresponding protein sequence and the primary EC number for each gene.
- Create an input table with columns:
Gene_ID,Reaction_ID,EC_Number,Protein_Sequence.
- Load the GEM using cobrapy (
Step 2: Running CataPro for kcat Prediction.
- Input: Table from Step 1.
- Procedure:
- For each unique EC number and protein sequence pair, query the CataPro model.
- Provide the protein sequence and the EC number as primary inputs.
- Record the predicted
kcat(in s⁻¹) for each query. For isozymes (multiple genes catalyzing the same reaction), predict a kcat for each and determine a representative value (e.g., maximum or mean) based on assumed expression. - Output a table:
Reaction_ID,Predicted_kcat,Gene_ID.
Step 3: Converting kcat to Turnover Constraints.
- Input: Predicted kcat table, GEM.
- Procedure:
- For each reaction, the predicted
kcatsets the upper bound for the reaction's catalytic capacity per unit enzyme. - The maximum reaction flux (
Vmax) is constrained by:Vmax ≤ kcat * [E], where[E]is the enzyme concentration. - In GEMs with absolute proteomics,
[E]can be used directly. More commonly, a unitless, relative "enzyme capacity" is used. Normalize all predictedkcatvalues by a reference value (e.g., median or glucose uptake kinase kcat) to create a consistent set of scaled capacity constraints. - For reversible reactions, apply the kcat as the forward and/or reverse limit based on the enzyme's mechanism, or split it using a Keq-derived ratio.
- For each reaction, the predicted
Step 4: Applying Constraints to the GEM and Performing Flux Analysis.
- Input: Constraint table, GEM.
- Procedure:
- Define the new constraint for each reaction. In cobrapy, this often involves modifying the reaction's upper (
model.reactions.RXN_ID.upper_bound) and lower bounds. For a pseudo-kinetic constraint, you may add it as a linear constraint on reaction fluxes weighted by the inverse of their kcat (an Enzyme Cost constraint). - Apply the constraints to the model.
- Perform Flux Balance Analysis (FBA) to compute optimal growth or other objectives.
- Validate predictions against experimental growth rates, substrate uptake/secretion rates, or gene essentiality data. Iteratively refine the constraint set (e.g., adjusting global scaling factor).
- Define the new constraint for each reaction. In cobrapy, this often involves modifying the reaction's upper (
Step 5: Advanced Analysis: Generating Condition-Specific Models.
- Input: Constrained GEM, transcriptomics/proteomics data.
- Procedure:
- Integrate omics data (e.g., RNA-seq) to estimate relative enzyme abundance
[E]under a specific condition. - Recalculate condition-specific
Vmaxconstraints:Vmax_condition = kcat_CataPro * [E]_relative. - Apply these new bounds to generate a context-specific model.
- Compare flux predictions across conditions (e.g., healthy vs. diseased, wild-type vs. knockout) to identify key metabolic differences and potential therapeutic targets.
- Integrate omics data (e.g., RNA-seq) to estimate relative enzyme abundance
4. Visualization of Workflows and Logical Relationships
CataPro-GEM Integration and Constraint Workflow
From Sequence to Flux Constraint Logical Pathway
Application Notes
Within the broader thesis on the CataPro deep learning model for enzyme kinetics prediction, this application focuses on in silico target prioritization for drug and antibiotic development. The core challenge is identifying enzymes crucial to pathogen viability or disease pathways while simultaneously possessing "druggable" kinetic and structural profiles. CataPro accelerates this by predicting catalytic efficiency (kcat/KM), inhibition constants (Ki), and the impact of mutations on these parameters, enabling virtual screening of enzyme targets before costly wet-lab experiments.
A primary application is combating antimicrobial resistance (AMR). For a bacterial pathogen, researchers can use CataPro to predict kinetics for all essential enzymes. Targets with predicted high flux control coefficients in vulnerable metabolic pathways (e.g., folate biosynthesis, cell wall assembly) are shortlisted. Subsequently, CataPro models the kinetic impact of potential inhibitors against these prioritized targets, ranking compounds by predicted efficacy. This approach is also applied to human disease enzymes, such as kinases in oncology, filtering for those with predicted favorable binding pockets and kinetic vulnerability.
The protocols below detail the integrated computational-experimental pipeline for validating a CataPro-prioritized enzyme target and lead inhibitor.
Protocols
Protocol 1:In SilicoTarget Triaging with CataPro
Objective: To rank potential enzyme targets from a pathogenic organism based on predicted essentiality and druggability.
Methodology:
- Input Dataset Curation: Compile a list of all enzymes from the target organism (e.g., Mycobacterium tuberculosis). Use databases like UniProt and essentiality data from DEG.
- CataPro Kinetics Prediction: For each enzyme, input sequence and (if available) structural data into CataPro. Obtain predictions for:
- Catalytic efficiency (kcat/KM)
- Thermodynamic stability (ΔΔG)
- Broad-spectrum conservation score (via integrated BLAST).
- Pathway Context Integration: Map enzymes to metabolic pathways (KEGG, MetaCyc). Use constraint-based modeling (e.g., via COBRApy) to predict metabolic flux control coefficients for each enzyme.
- Druggability Assessment: For high-value pathway targets, use CataPro to predict the kinetic impact (change in kcat/KM) of a library of scaffold-like molecules derived from the model's training data.
- Prioritization Score: Calculate a composite score: Priority Score = (Essentiality Index) x (Flux Control Coefficient) x (Predicted Druggability Index).
Table 1: CataPro-Prioritized Enzyme Targets for Staphylococcus aureus
| Enzyme (EC Number) | Pathway | Predicted kcat/KM (M-1s-1) | Essentiality | Predicted Druggability Index (0-1) | Composite Priority Score |
|---|---|---|---|---|---|
| Dihydropteroate synthase (2.5.1.15) | Folate biosynthesis | 1.2 x 105 | Yes | 0.87 | 9.8 |
| MurA (UDP-N-acetylglucosamine enolpyruvyl transferase) (2.5.1.7) | Peptidoglycan biosynthesis | 8.5 x 104 | Yes | 0.92 | 9.5 |
| β-Ketoacyl-acyl carrier protein synthase III (FabH) (2.3.1.180) | Fatty acid biosynthesis | 7.3 x 104 | Yes | 0.45 | 4.1 |
Protocol 2: Experimental Validation of a Prioritized Target and Inhibitor
Objective: To express, purify, and kinetically characterize a CataPro-prioritized enzyme and validate a top-predicted inhibitor in vitro and in vivo.
Part A: Recombinant Enzyme Production & Steady-State Kinetics
- Gene Cloning: Codon-optimize and clone the gene encoding the prioritized target (e.g., folP from S. aureus) into a pET expression vector.
- Protein Expression & Purification: Transform into E. coli BL21(DE3). Induce with 0.5 mM IPTG at 16°C for 18h. Purify via Ni-NTA affinity and size-exclusion chromatography.
- Steady-State Kinetics: Perform Michaelis-Menten assays. For DHPS, monitor consumption of para-aminobenzoic acid (pABA) spectrophotometrically. Fit data to obtain experimental kcat and KM.
- Inhibition Assays: Titrate the CataPro-top-ranked inhibitor (e.g., a sulfonamide analog). Perform dose-response assays to determine IC50. Conduct competitive inhibition assays to determine experimental Ki.
Table 2: Experimental vs. CataPro-Predicted Kinetics for S. aureus DHPS
| Parameter | Experimental Value | CataPro Predicted Value | % Deviation |
|---|---|---|---|
| kcat (s-1) | 12.5 ± 0.8 | 14.1 | +12.8% |
| KM for pABA (µM) | 18.2 ± 1.5 | 15.7 | -13.7% |
| kcat/KM (M-1s-1) | 6.9 x 105 | 9.0 x 105 | +30.4% |
| Ki for Inhibitor X (nM) | 42 ± 5 | 38 | -9.5% |
Part B: In Vivo Minimum Inhibitory Concentration (MIC) Determination
- Broth Microdilution: Prepare Mueller-Hinton II broth according to CLSI guidelines. Prepare a 2-fold serial dilution of the validated inhibitor in a 96-well plate.
- Inoculum Preparation: Adjust a mid-log phase culture of S. aureus (ATCC 29213) to 5 x 105 CFU/mL.
- Incubation & Reading: Add inoculum to each well. Incubate at 37°C for 18-20h. The MIC is the lowest concentration that prevents visible growth.
Visualizations
Diagram Title: CataPro Enzyme Target Prioritization Workflow
Diagram Title: DHPS in Folate Pathway and Inhibition Site
The Scientist's Toolkit
Table 3: Key Research Reagent Solutions for Target Validation
| Item | Function in Protocol | Example Product/Source |
|---|---|---|
| Codon-Optimized Gene Fragment | Ensures high-yield expression of the pathogenic enzyme in E. coli heterologous systems. | Integrated DNA Technologies (IDT) gBlocks, Twist Bioscience. |
| pET Expression Vector | A T7 promoter-based plasmid for high-level, inducible protein expression in E. coli. | Novagen pET-28a(+) (Merck Millipore). |
| Ni-NTA Superflow Resin | Immobilized metal affinity chromatography (IMAC) resin for purifying His-tagged recombinant enzymes. | Qiagen, Cytiva HisTrap HP. |
| Size-Exclusion Chromatography Column | For final polishing step to obtain monodisperse, aggregate-free enzyme for kinetics. | Cytiva HiLoad 16/600 Superdex 200 pg. |
| Spectrophotometric Enzyme Assay Kit | Pre-optimized reagent mix for specific enzyme activity (e.g., DHPS), enabling rapid initial screening. | Custom assays from Sigma-Aldrich or Cayman Chemical. |
| Microplate Reader (UV-Vis) | High-throughput instrument for performing kinetic reads of enzyme activity and inhibition assays. | BioTek Synergy H1, Molecular Devices SpectraMax. |
| Cation-Adjusted Mueller-Hinton II Broth | Standardized medium for determining Minimum Inhibitory Concentration (MIC) per CLSI guidelines. | BD Bacto, Thermo Fisher. |
The CataPro deep learning model, developed as the core of this thesis research, predicts enzyme kinetic parameters (kcat, KM) from protein sequence and structural features. This predictive capability directly addresses a central bottleneck in directed evolution: the need for high-throughput, accurate functional screening. Traditional campaigns rely on resource-intensive assays to measure improved variants. By integrating CataPro’s in silico kinetic predictions, researchers can prioritize variants with predicted enhanced catalytic efficiency and stability before experimental characterization, dramatically accelerating the design-build-test-learn (DBTL) cycle for protein engineering.
Application Notes: Integrating CataPro into a Directed Evolution Workflow
Objective: To evolve a halohydrin dehalogenase (HHDH) for increased activity on a non-native epoxide substrate toward the synthesis of a β-blocker precursor.
CataPro Integration Points:
- Variant Library Pre-screening: After generating a diverse mutant library (e.g., via site-saturation mutagenesis at hotspots), CataPro predicts the kcat/KM for each variant toward the target substrate. The top 100 in silico predicted hits are selected for experimental testing, bypassing the need to screen >10,000 clones via primary assay.
- Fitness Function Definition: The predicted kcat/KM value serves as a primary computational fitness score, guiding the selection of parents for subsequent recombination rounds.
- Mechanistic Insight: Analysis of CataPro’s attention weights for top-performing variants can highlight structurally or dynamically important residues beyond the active site, informing the next round of rational design.
Quantitative Impact Summary:
| Metric | Traditional Directed Evolution | CataPro-Guided Campaign (Simulated) | Improvement Factor |
|---|---|---|---|
| Initial Library Size | ~50,000 variants | ~50,000 variants | 1x |
| Primary Experimental Screens | ~50,000 assays | ~100 assays | 500x reduction |
| Time to Identify Top 100 Hits | 4-6 weeks | 1 week (compute + focused assay) | 4-6x faster |
| Overall Campaign Duration | 9-12 months | 3-5 months (projected) | 2-3x faster |
| Hit Rate (Variants with >2x improved activity) | ~0.5% | ~25% (enriched post-screening) | 50x enrichment |
Experimental Protocols
Protocol 1: High-Throughput Kinetic Screening of CataPro-Prioritized Variants
Objective: Experimentally validate the kinetic parameters of computationally prioritized HHDH variants.
Materials: See "Scientist's Toolkit" below. Procedure:
- Gene Library Construction: Perform site-saturation mutagenesis at target residues (e.g., using NNK codons). Clone into an expression vector (e.g., pET-28a(+)).
- CataPro Prediction & Selection: Input the sequence of all 50,000 variants into CataPro. Receive predictions for kcat and KM. Select the top 100 variants ranked by predicted kcat/KM.
- Focused Expression: Transform the plasmids for the 100 selected variants into E. coli BL21(DE3). Inoculate deep-well plates with auto-induction media. Express at 25°C for 20h.
- Lysate Preparation: Pellet cells by centrifugation. Lyse via chemical lysis (BugBuster Master Mix) or sonication. Clarify lysates by centrifugation.
- Coupled Spectrophotometric Assay: In a 96-well plate, mix:
- 90 µL of assay buffer (100 mM Tris-SO4, pH 8.0)
- 50 µL of clarified lysate
- 50 µL of NADH regeneration mix (2 mM NAD+, 20 mM glucose, 2 U/mL GDH)
- 10 µL of substrate (epoxide) at varying concentrations (0.2-10 mM, from a stock in DMSO).
- Initiate reaction by adding substrate. Monitor the decrease in absorbance at 340 nm (NADH consumption) for 5 minutes using a plate reader.
- Data Analysis: Calculate initial velocities (v0). Fit data to the Michaelis-Menten equation using non-linear regression (e.g., in GraphPad Prism) to determine experimental KM and kcat values.
- Validation: Compare experimental kinetics with CataPro predictions to refine the model and confirm hit variants.
Protocol 2: Recombination & Iteration Based on CataPro Fitness Scores
Objective: Generate a second-generation library by recombining beneficial mutations from validated hits.
- Parent Selection: Choose 5-10 validated hit variants with the highest experimental kcat/KM as parents.
- DNA Shuffling: Fragment the parent genes using DNase I. Reassemble via PCR without primers (assembly PCR). Amplify the full-length chimeric genes with flanking primers.
- Next-Round Prediction: Sequence a random subset (~1000) of the shuffled library. Input these sequences into CataPro for prediction. Select the top 50 predicted performers for the next experimental screening loop (Protocol 1).
Visualizations
Diagram 1: CataPro-Guided Directed Evolution DBTL Cycle
Diagram 2: High-Throughput Kinetic Validation Workflow
The Scientist's Toolkit
| Research Reagent / Material | Function in Protocol |
|---|---|
| NNK Degenerate Oligonucleotides | Encodes all 20 amino acids at targeted codon during site-saturation mutagenesis. |
| pET-28a(+) Vector | High-copy E. coli expression vector with T7 promoter for strong, inducible protein production. |
| E. coli BL21(DE3) Cells | Expression host containing genomic T7 RNA polymerase for IPTG or auto-induction. |
| Terrific Broth (TB) Auto-induction Media | Supports high-density cell growth and automatic induction of protein expression. |
| BugBuster Master Mix | Ready-to-use reagent for chemical lysis of E. coli to release soluble enzyme. |
| NADH Regeneration System (NAD+, Glucose, GDH) | Couples product formation to NADH oxidation, enabling continuous spectrophotometric readout at 340 nm. |
| Microplate Spectrophotometer | Instrument for high-throughput kinetic measurements in 96- or 384-well format. |
| GraphPad Prism Software | For statistical analysis and non-linear regression fitting of kinetic data to models. |
Overcoming Limits: Expert Strategies for Optimizing CataPro Performance
A core thesis of the CataPro deep learning initiative is to transcend traditional homology-based limitations in enzyme kinetic parameter (kcat, KM) prediction. While models trained on expansive datasets like SABIO-RK perform well for well-characterized families, their predictive power collapses for enzymes with low sequence homology to training examples or for novel enzyme families (e.g., discovered via metagenomics) where kinetic data is sparse or non-existent. This pitfall directly undermines the goal of a universally applicable in silico enzyme kinetics predictor. This document outlines application notes and protocols to identify, validate, and mitigate this challenge within CataPro model development and deployment.
Diagnostic Indicators & Quantitative Assessment
The following metrics, calculated on hold-out validation sets, signal susceptibility to the low-homology pitfall.
Table 1: Diagnostic Metrics for Identifying Low-Homology Performance Decay
| Metric | Standard Family (e.g., TIM Barrel) | Low-Homology/Novel Family | Interpretation |
|---|---|---|---|
| Mean Absolute Error (MAE) on log(kcat) | 0.4 - 0.7 log units | > 1.5 log units | Predictions are off by more than an order of magnitude. |
| Prediction vs. Experiment Correlation (R²) | > 0.6 | < 0.2 | Model fails to capture rank-order kinetic trends. |
| Per-Family Performance Variance | Low | Exceptionally High | Performance is inconsistent and unpredictable across clusters. |
| Sequence Identity to Nearest Training Neighbor | > 40% | < 20% | Primary sequence offers limited direct learning signal. |
Experimental Protocols for Validation & Mitigation
Protocol: Controlled Hold-Out Validation for Novelty Detection
Objective: To quantitatively assess CataPro's performance drop on enzyme clusters deliberately excluded from training. Materials: Curated enzyme kinetics dataset (e.g., from BRENDA, SABIO-RK), CataPro model weights, clustering software (e.g., MMseqs2, CD-HIT). Procedure:
- Cluster Definition: Cluster the full enzyme sequence dataset at strict identity thresholds (e.g., 30%, 25%, 20%).
- Strategic Data Splitting: Instead of random split, hold out entire clusters (families) from training. Reserve 5-10% of clusters as the "novel family" test set.
- Model Training: Train CataPro exclusively on the remaining clusters.
- Targeted Evaluation: Evaluate model performance on the held-out clusters. Calculate metrics from Table 1 separately for held-out vs. training-like clusters.
- Analysis: Plot performance (MAE) against the mean sequence identity of the held-out cluster to its nearest neighbor in the training set.
Protocol: Active Learning Loop for Targeted Data Acquisition
Objective: To strategically guide wet-lab experimentation to acquire the most informative new kinetic data for model improvement. Materials: Pretrained CataPro model, pool of uncharacterized enzyme sequences, uncertainty quantification module (e.g., Monte Carlo Dropout, ensemble variance). Procedure:
- Uncertainty Sampling: Use the trained CataPro to predict on the pool of uncharacterized enzymes. Record both the prediction and the model's predictive uncertainty (variance).
- Priority Ranking: Rank enzymes by highest predictive uncertainty. These are points in "sequence space" where the model is least confident, often corresponding to low-homology regions.
- Batch Selection: Select the top N (e.g., 20-50) enzyme candidates for experimental characterization.
- Experimental Characterization: (See Section 4.0 for kinetic assay protocol).
- Model Retraining: Integrate the new, high-value kinetic data into the training set. Fine-tune or retrain the CataPro model.
- Iteration: Repeat steps 1-5 for successive cycles, monitoring performance improvement on a fixed benchmark set of novel families.
Protocol:kcatDetermination via Coupled Spectrophotometric Assay
Objective: To generate high-quality kinetic data for novel enzymes to feed into CataPro training. Materials: Purified novel enzyme, substrate, coupling enzyme system, spectrophotometer with temperature control, assay buffer. Procedure:
- Reaction Design: Design a coupled assay where the product of the novel enzyme reaction is the substrate for a well-characterized coupling enzyme, resulting in a measurable change in absorbance (e.g., NADH NAD⁺ at 340 nm).
- Preliminary Assay: Establish linearity of signal with time and enzyme concentration. Ensure the coupling system is not rate-limiting.
- Initial Rate Measurements: For a fixed, saturating substrate concentration, measure initial velocity (V₀) across a range of enzyme concentrations to verify proportionality.
- Steady-State Kinetics: For a fixed enzyme concentration, measure V₀ across a range of substrate concentrations ([S]).
- Data Analysis: Fit the Michaelis-Menten equation (V₀ = (Vmax [S]) / (KM + [S])) to the data using non-linear regression. kcat is calculated as Vmax / [Enzyme], where [Enzyme] is the molar concentration of active sites.
Visualization of Strategies & Workflows
Diagram 1: CataPro Active Learning Cycle for Novel Enzymes
Diagram 2: Diagnostic Pipeline for Low-Homology Pitfall
The Scientist's Toolkit: Key Reagent Solutions
Table 2: Essential Reagents for Validating & Overcoming the Pitfall
| Reagent / Material | Function / Purpose | Application in Protocol |
|---|---|---|
| High-Quality Enzyme Kinetics Databases (SABIO-RK, BRENDA) | Provides structured, annotated data for training and benchmark construction. | 3.1 (Controlled Hold-Out) |
| Sequence Clustering Tool (MMseqs2) | Enables family-level partitioning of data based on sequence similarity. | 3.1 (Controlled Hold-Out) |
| Uncertainty Quantification Library (e.g., PyTorch with MC Dropout) | Quantifies model prediction confidence, enabling active learning. | 3.2 (Active Learning) |
| Coupled Enzyme Assay Kits (e.g., for dehydrogenases, kinases) | Provides reliable, optimized systems to measure novel enzyme activity. | 3.3 (kcat Determination) |
| UV-Vis Spectrophotometer with Peltier Control | Enables precise, temperature-controlled kinetic measurements. | 3.3 (kcat Determination) |
| High-Fidelity Protein Expression & Purification System | Yields pure, active novel enzyme for kinetic characterization. | 3.3 (kcat Determination) |
| Automated Liquid Handling Workstation | Increases throughput and reproducibility of kinetic assays for data acquisition. | 3.2 & 3.3 |
Within the CataPro deep learning framework for enzyme kinetics prediction, a critical challenge lies in interpreting the model's raw prediction scores. These scores, while indicative, are not direct measures of experimental confidence. This document provides application notes and protocols for calibrating these scores to determine when a prediction can be trusted for in silico guidance and when it necessitates wet-lab validation. Proper calibration is paramount for efficient resource allocation in enzyme engineering and drug discovery pipelines.
Table 1: CataPro Benchmark Performance on Diverse Enzyme Families
| Enzyme Class (EC Number) | Test Set Size | RMSE (ΔΔG‡) | R² | Mean Prediction Score (0-1) | Confidence Threshold (Recommended) |
|---|---|---|---|---|---|
| EC 1.1.1 (Oxidoreductases) | 450 | 1.28 kcal/mol | 0.87 | 0.78 | 0.85 |
| EC 2.7.1 (Transferases) | 380 | 1.41 kcal/mol | 0.82 | 0.72 | 0.80 |
| EC 3.4.1 (Hydrolases) | 520 | 1.15 kcal/mol | 0.89 | 0.81 | 0.88 |
| EC 4.1.1 (Lyases) | 210 | 1.52 kcal/mol | 0.79 | 0.68 | 0.75 |
| Overall (Averaged) | 1560 | 1.34 kcal/mol | 0.84 | 0.75 | 0.82 |
Table 2: Calibration Error Metrics Across Prediction Score Bins
| Prediction Score Bin | Number of Predictions | Expected Accuracy (%) | Observed Accuracy (%) | Calibration Error ( | Δ | ) | Recommended Action |
|---|---|---|---|---|---|---|---|
| 0.90 - 1.00 | 12,450 | 95.0 | 94.7 | 0.3 | Trust for design | ||
| 0.75 - 0.89 | 28,110 | 82.0 | 78.5 | 3.5 | Trust with caution | ||
| 0.60 - 0.74 | 41,330 | 67.0 | 62.1 | 4.9 | Seek validation | ||
| 0.40 - 0.59 | 35,670 | 50.0 | 45.3 | 4.7 | Require validation | ||
| 0.00 - 0.39 | 22,440 | 20.0 | 18.9 | 1.1 | Do not trust; redesign |
Core Protocols
Protocol 3.1: Model-Guided Decision Workflow for Experimental Validation
Objective: To systematize the decision to pursue experimental kinetics validation based on CataPro outputs.
Materials: CataPro prediction report (containing prediction score, estimated ΔΔG‡, sequence similarity metrics), target enzyme expression system, kinetic assay reagents (see Toolkit, Section 5).
Procedure:
- Input & Pre-screen: Input mutant sequence/structure into CataPro. Ensure input passes basic quality checks (no gaps, valid PDB format).
- Generate Prediction: Run the CataPro deep learning model to obtain: (i) Predicted ΔΔG‡ (activation energy change), (ii) Raw prediction score (0-1), (iii) Model uncertainty metric (epistemic variance).
- Apply Calibration Filter:
- IF Prediction Score ≥ Threshold T1 (e.g., 0.82 from Table 1) AND Model Uncertainty < 0.1 → Category A: High-Trust Prediction. Proceed to computational design pipeline. Optional: Validate a random subset (<5%) for continuous monitoring.
- IF Prediction Score is between Threshold T2 (0.60) and T1 (0.82) → Category B: Moderate-Trust Prediction. These require experimental validation. Proceed to Protocol 3.2.
- IF Prediction Score < Threshold T2 (0.60) → Category C: Low-Trust Prediction. Return to model for alternative sequence design or investigate input quality.
- Prioritize Validation Queue: For Category B predictions, prioritize experiments based on the magnitude of the predicted ΔΔG‡ (greatest predicted improvement first) and project goals.
Diagram: CataPro Prediction Trust Decision Workflow
Protocol 3.2: Experimental Validation of Moderate-Trust Predictions
Objective: To experimentally determine Michaelis-Menten kinetics (kcat, KM) for mutant enzymes flagged for validation.
Part A: Protein Expression & Purification
- Expression: Transform expression vector (e.g., pET series in E. coli BL21(DE3)) with mutant gene. Induce expression with 0.5 mM IPTG at 16°C for 18h.
- Lysis & Clarification: Lyse cells via sonication in Lysis Buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mM PMSF). Clarify at 20,000 x g for 30 min at 4°C.
- Purification: Pass supernatant over HisTrap HP column. Wash with 20 column volumes (CV) Wash Buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 40 mM imidazole). Elute with Elution Buffer (same as Wash, but 300 mM imidazole).
- Buffer Exchange & Quantification: Desalt into Assay Buffer (protocol-specific) using PD-10 columns. Determine concentration via A280.
Part B: Continuous Coupled Kinetics Assay (Example for Dehydrogenase)
- Reaction Mix: In a quartz cuvette, add: 980 µL of Assay Buffer (100 mM phosphate pH 7.5), 10 µL of 100 mM NAD⁺, 5 µL of purified enzyme (diluted to expected activity range).
- Baseline: Monitor absorbance at 340 nm (A₃₄₀) for 60 sec at 25°C.
- Initiation: Rapidly add 5 µL of 1M substrate (e.g., ethanol for ADH) to start reaction. Mix immediately.
- Data Acquisition: Record A₃₄₀ every 5 sec for 5 min. The linear rate of A₃₄₀ increase is proportional to velocity (v), using ε₃₄₀(NADH) = 6220 M⁻¹cm⁻¹.
- KM Determination: Repeat steps 1-4 across a minimum of 8 substrate concentrations (e.g., 0.1KM to 5KM). Maintain non-saturating conditions for coupling enzymes.
Part C: Data Analysis & Calibration Feedback
- Fit v vs. [S] data to the Michaelis-Menten equation (non-linear regression) to extract kcat and KM.
- Calculate experimental ΔΔG‡ = -RT ln( (kcat/KM)mut / (kcat/KM)wt ).
- Compare to Prediction: Plot experimental ΔΔG‡ vs. predicted ΔΔG‡ for all validated mutants. Calculate calibration statistics (ECE, MCE) to update the CataPro post-hoc calibration layer.
Diagram: Experimental Validation & Calibration Feedback Loop
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Validation Protocols
| Item | Example Product/Catalog # | Function in Protocol |
|---|---|---|
| Expression Vector | pET-28a(+) (Novagen) | High-level, inducible expression of His-tagged mutant enzymes. |
| Competent Cells | E. coli BL21(DE3) Gold (Agilent) | Robust protein expression strain with T7 polymerase. |
| Affinity Chromatography Resin | HisTrap HP, 5 mL (Cytiva) | Immobilized metal affinity chromatography for rapid purification. |
| Desalting Column | PD-10 Desalting Columns (Cytiva) | Buffer exchange into kinetically compatible assay buffer. |
| Cofactor Substrate | β-Nicotinamide adenine dinucleotide, NAD⁺ (Sigma N7004) | Essential cofactor for dehydrogenase coupled assays. |
| UV-Vis Spectrophotometer | Agilent Cary 3500 | For precise, temperature-controlled absorbance kinetics measurements. |
| Cuvettes | Quartz, 10 mm path length, 1 mL volume (Hellma) | Required for accurate UV absorbance readings at 340 nm. |
| Data Analysis Software | GraphPad Prism v10+ | Non-linear regression for fitting kinetic data to models. |
Within the broader thesis on the CataPro deep learning platform for enzyme kinetics prediction, a core challenge is model specialization. While the base CataPro model demonstrates robust general predictive capability for Michaelis-Menten parameters (kcat, KM), its performance can be optimized for critical, high-value target classes through advanced parameter tuning. This application note details protocols for the organism-specific and class-specific tuning of CataPro, using the human kinome as a primary case study. This process tailors the model's feature weighting, regularization, and latent space representation to the unique physicochemical and structural fingerprints of the target class, significantly enhancing prediction accuracy for drug discovery pipelines.
The Need for Specialized Tuning: The Human Kinase Example
Human kinases represent one of the most prominent drug target families, with over 500 members regulating crucial signaling pathways. Despite a conserved catalytic core, kinases exhibit vast diversity in substrate specificity, regulatory mechanisms, and dynamics. A generic deep learning model may overlook subtle, family-specific determinants of catalytic efficiency. Tuning addresses this by aligning the model's inductive bias with domain knowledge.
Quantitative Justification for Tuning
The following table summarizes the performance lift achieved by a kinase-tuned CataPro model versus the base model on a held-out test set of human kinase kinetic parameters (compiled from public databases like BRENDA and PKIDB).
Table 1: Performance Comparison of Base vs. Kinase-Tuned CataPro Model
| Model Variant | MAE for log(kcat) | RMSE for log(kcat) | MAE for log(KM) | RMSE for log(KM) | Spearman's ρ (kcat) | Spearman's ρ (KM) |
|---|---|---|---|---|---|---|
| CataPro (Base) | 0.89 | 1.15 | 0.94 | 1.22 | 0.71 | 0.68 |
| CataPro (Kinase-Tuned) | 0.52 | 0.72 | 0.61 | 0.83 | 0.88 | 0.85 |
MAE: Mean Absolute Error; RMSE: Root Mean Square Error; Data derived from ~4,500 kinetic entries for ~120 human kinases.
Protocol: Tuning CataPro for Human Kinases
This protocol outlines the end-to-end process for generating a kinase-specialized CataPro model.
Phase 1: Curation of a Specialized Kinase Kinetics Dataset
Objective: Assemble a high-quality, balanced dataset for training and validation.
- Data Source Aggregation: Programmatically access and merge entries from:
- BRENDA: Filter for organism "Homo sapiens" and EC class 2.7.*.
- PKIDB: Extract all kinetic data.
- ChEMBL: Extract bioactivity data with annotated enzyme parameters.
- Literature Mining: Use NLP scripts (e.g., using SLAPenzyme database queries) to extract parameters from full-text articles.
- Data Standardization:
- Convert all kcat and KM values to common units (s⁻¹ and µM, respectively).
- Apply log10 transformation to both parameters to normalize distributions.
- Map all substrates and kinases to standard identifiers (UniProt ID for enzymes, ChEBI or PubChem CID for substrates).
- Descriptor Calculation: For each kinase-substrate pair, generate:
- Sequence-based Features: Use the base CataPro pipeline to compute embeddings from the kinase amino acid sequence.
- Structure-based Features: If an X-ray/cryo-EM structure (apo or bound) is available in the PDB, compute:
- Active site pocket volume and electrostatic potential (using P2Rank & APBS).
- DFG and A-loop conformation labels (DFG-in/out, A-loop open/closed).
- Substrate Descriptors: Extended-connectivity fingerprints (ECFP4) and topological polar surface area for the substrate molecule.
- Dataset Splitting: Perform a kinase-stratified split to ensure no kinase in the test set appears in training.
- Training Set: 70% of kinases and their associated data.
- Validation Set: 15% of kinases.
- Test Set: 15% of kinases.
Phase 2: Model Architecture Adjustment & Transfer Learning
Objective: Modify the CataPro architecture and initiate training from a pre-trained checkpoint.
- Base Model Loading: Load the weights of the pre-trained, generalist CataPro model.
- Architecture Modification:
- Add kinase-family-specific auxiliary input heads. These are small neural networks that take as input the primary sequence embedding and predict kinase family (e.g., TK, TKL, STE, CK1, AGC, CAMK, CMGC). The loss from this auxiliary task encourages the model to learn family-relevant features.
- Introduce an attention layer over the enzyme embedding to dynamically weight active site residues identified from a multiple sequence alignment of the human kinome.
- Transfer Learning Protocol:
- Step 1 (Feature Extractor Fine-tuning): Freeze all layers of the loaded model except the final multi-task prediction heads. Train for 50 epochs on the kinase training set using a reduced learning rate (1e-4). Use Mean Squared Error (MSE) loss for kcat/KM and cross-entropy for the auxiliary family classification.
- Step 2 (Full Model Fine-tuning): Unfreeze all layers. Train for an additional 150 epochs with an even lower learning rate (1e-5) and early stopping based on the validation loss. Employ L2 regularization (λ=0.01) specific to the newly added layers to prevent overfitting.
Phase 3: Validation & Interpretation
Objective: Rigorously assess the tuned model and interpret its decisions.
- Performance Benchmarking: Evaluate on the held-out kinase test set (metrics as in Table 1).
- SHAP Analysis: Use SHapley Additive exPlanations (SHAP) on the validation set to identify which input features (e.g., specific residue positions, substrate fingerprint bits) most strongly influence predictions for different kinase families.
- In-silico Mutagenesis: Systematically mutate key residues (e.g., the catalytic Asp, gatekeeper residues) in the model's input sequence and predict the effect on kcat and KM, validating trends against known biochemical literature.
The Scientist's Toolkit: Key Reagent Solutions
Table 2: Essential Research Reagents & Materials for Kinase Kinetics & Model Validation
| Item | Function/Description | Example Product/Catalog |
|---|---|---|
| Recombinant Human Kinase (Active) | Purified, full-length or catalytic domain protein for in vitro kinetic assays. Essential for generating new validation data. | SignalChem (e.g., SRC, SYK), Invitrogen (SelectScreen Kinase Profiling Services). |
| ATPase/GTPase Activity Assay Kit | Homogeneous, coupled-enzyme assay to continuously monitor phosphate production for kcat/KM determination. | Cytoskeleton, Inc. Cat. # BK100; Promega ADP-Glo Kinase Assay. |
| Phospho-Specific Substrate Antibodies | For endpoint kinetic assays using non-fluorescent substrates, enabling detection of phosphorylated product by ELISA or Western. | Cell Signaling Technology phospho-antibodies. |
| Kinase Inhibitor Set (Tool Compounds) | Validated, potent inhibitors for specific kinase families. Used as controls to confirm enzyme activity and assay specificity. | Selleckchem Kinase Inhibitor Library; Tocris Staurosporine, Dasatinib. |
| Microfluidic Calorimetry Chip (ITC) | For direct measurement of substrate binding affinity (KD), which can inform KM validation under specific conditions. | Malvern MicroCal PEAQ-ITC. |
| TR-FRET Kinase Assay Kits | Time-Resolved Fluorescence Resonance Energy Transfer assays for high-throughput kinetic screening in drug discovery settings. | CisBio KinaSure kits. |
Visualizations
Workflow for Tuning CataPro on Human Kinases
Modified CataPro Architecture with Kinase-Specific Layers
This application note addresses a critical phase in our broader thesis on the CataPro deep learning model. CataPro predicts enzyme turnover numbers (kcat) from protein sequence and structure, generating high-throughput in silico kinetic profiles. The core research challenge is the systematic experimental validation and integration of these predictions to create a closed-loop, model-improving pipeline. Successful bridging of this gap is essential for establishing CataPro as a credible tool for enzyme engineering, metabolic modeling, and drug discovery, where accurate kinetics are paramount.
Foundational Concepts & Data Comparison
Table 1: Comparison of Predicted vs. Experimental kcat Value Ranges
| Enzyme Class (EC) | Typical Experimental kcat Range (s⁻¹) | CataPro Prediction Error (Mean Absolute Error on Log10 Scale) | Key Experimental Assay Interference Factors |
|---|---|---|---|
| Oxidoreductases (EC 1) | 10⁻² – 10³ | ±0.85 log units | Substrate auto-oxidation, cofactor regeneration, enzyme inactivation by reactive oxygen species. |
| Transferases (EC 2) | 10⁻¹ – 10² | ±0.72 log units | Endogenous activity in cell lysates, isotope effect in radiometric assays, donor substrate limitation. |
| Hydrolases (EC 3) | 1 – 10⁴ | ±0.65 log units | pH shift artifacts, coupled enzyme kinetics, non-specific hydrolysis. |
| Lyases (EC 4) | 0.1 – 10³ | ±0.80 log units | Non-enzymatic substrate decay, reverse reaction, product inhibition. |
| Isomerases (EC 5) | 10⁻¹ – 10² | ±0.70 log units | Equilibrium limitations, difficulty in distinguishing substrate from product. |
Table 2: Decision Matrix for Assay Selection Based on CataPro Output
| CataPro Prediction Confidence (Score) | Predicted kcat Range (s⁻¹) | Recommended Primary Assay | Throughput | Key Validation Consideration |
|---|---|---|---|---|
| High (>0.8) | > 10 | Direct, continuous spectrophotometric/fluorimetric | High | Verify linearity over first 10% of reaction; use multiple [S]. |
| High (>0.8) | < 1 | Coupled enzyme or HPLC/MS | Medium | Optimize coupling enzyme ratio; ensure product detection sensitivity. |
| Medium (0.5-0.8) | Any | Microplate-based coupled assay or ISC (see Protocol 1) | High | Include stringent negative controls (e.g., active site mutant). |
| Low (<0.5) | Any | Calorimetric (ITC) or direct product detection (HPLC/MS) | Low | Focus on kcat/KM determination; may require purified native substrate. |
Core Experimental Protocols
Protocol 1: Initial Screening Calorimetry (ISC) for Low-Confidence Predictions
Purpose: To experimentally obtain a kcat value without optical handles or coupled systems, ideal for validating predictions where substrate/product optical changes are absent.
Reagent Solutions:
- Assay Buffer: 50 mM HEPES, pH 7.5, 100 mM NaCl. Filter (0.22 µm) and degas under vacuum for 15 min.
- Enzyme Stock: Purified enzyme at 50-100 µM in dialysis buffer. Centrifuge (14,000 x g, 4°C, 10 min) before use.
- Substrate Stock: Prepared in identical degassed buffer at 10x the highest test concentration.
Methodology:
- Load the reference cell (ITC instrument) with degassed assay buffer.
- Fill the sample cell with substrate solution at concentration [S] >> KM (estimated from CataPro's companion KM prediction or literature).
- Equilibrate at assay temperature (e.g., 25°C) with constant stirring (750 rpm).
- Perform a single injection of concentrated enzyme stock (typical 20-50 µL) to initiate the reaction.
- Measure the total heat flow (µJ/sec) over time until the signal returns to baseline.
- Calculate kcat: Total integrated heat (J) = ΔH * moles of product formed. Moles product = moles enzyme active sites injected * (1 - e^(-kcat * t)). Fit the progress curve to solve for kcat.
Protocol 2: Orthogonal Validation using Stopped-Flow Spectrophotometry
Purpose: To confirm kcat for fast reactions (predicted kcat > 100 s⁻¹) and capture rapid kinetic phases.
Reagent Solutions:
- Anaerobic Buffer: Prepare buffer in a septum-sealed flask and sparge with argon for 30 min. Use gas-tight syringes.
- Enzyme Solution: Purified enzyme in anaerobic buffer, pre-incubated in driving syringe.
- Substrate/Cofactor Solution: Mixed in second driving syringe.
Methodology:
- Load syringes with enzyme and substrate solutions, ensuring no air bubbles.
- Set instrument to rapid mixing mode (1:1 ratio, dead time < 2 ms).
- Perform 5-10 replicate shots at a single wavelength (e.g., NADH oxidation at 340 nm).
- Average the transient traces.
- Fit the exponential phase of the progress curve (first 5-50 ms) to the equation: Abst = A * e^(-kobs * t) + C, where k_obs approximates kcat under saturating conditions ([S] > 10*KM).
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Integration Workflow
| Item | Function & Rationale |
|---|---|
| HIS-tagged Purification System | Enables rapid, standardized purification of wild-type and mutant enzymes for consistent specific activity determination. |
| Thermostable Coupling Enzymes (e.g., from thermophiles) | Reduces background noise in coupled assays by minimizing denaturation during long incubations. |
| Deuterated Internal Standards (for LC-MS) | Enables absolute quantification of product formation for assays without optical changes, critical for low kcat validation. |
| Microfluidic Droplet Generators | Allows ultra-high-throughput compartmentalization of single enzyme molecules with substrates, enabling direct kcat measurement from fluorescence accumulation. |
| Active-Site Mutant (e.g., S→A) Control | Genetically engineered enzyme with catalytic residue mutated. Serves as the essential negative control to rule out non-enzymatic or background activity. |
| Cofactor Regeneration Systems (e.g., PDH for NADH) | Maintains constant cofactor concentration in oxidoreductase assays, preventing kcat underestimation due to cofactor depletion. |
Visualization: Integration Workflow & Pathway
CataPro-Experiment Integration Workflow
Enzymatic Reaction with Measurement Points
Within the broader thesis exploring the CataPro deep learning model for high-fidelity enzyme kinetics prediction—a critical tool in rational drug design and metabolic engineering—this document provides essential Application Notes and Protocols. Efficient computational resource management is paramount for scaling CataPro's training on large, diverse enzyme sequence-structure-kinetics datasets and for high-throughput virtual screening. The choice between local high-performance computing (HPC) clusters and cloud platforms involves critical trade-offs in cost, performance, data governance, and operational flexibility that directly impact research velocity and reproducibility.
Quantitative Comparison: Local HPC vs. Cloud Services
Table 1: Cost-Benefit Analysis for CataPro Model Training (2024 Data)
| Aspect | Local HPC Cluster | Cloud Service (e.g., AWS, GCP, Azure) |
|---|---|---|
| Capital Expenditure (CapEx) | High initial investment (~$50k - $500k+ for dedicated hardware). | Near-zero. |
| Operational Expenditure (OpEx) | Moderate (power, cooling, maintenance, ~$5k - $20k/yr). | Pay-per-use; highly variable. Example: Training CataPro on 8x NVIDIA A100 for 1 week ~$2,500 - $3,500. |
| Performance & Hardware | Fixed, potential for rapid obsolescence. Queue times can delay jobs. | On-demand access to latest accelerators (e.g., H100, A100). Minimal queue times. |
| Data Security & Control | High. Data remains on-premises, ideal for proprietary IP. | Shared responsibility model. Potential compliance concerns (HIPAA, GDPR). |
| Scalability | Limited to installed capacity. Scaling requires new procurement. | Essentially infinite, elastic scaling within minutes. |
| Administrative Overhead | High. Requires dedicated IT staff for management, software stack. | Low for users, handled by provider. |
| Best for CataPro Use-Case | Long-term, large-scale projects with stable funding and sensitive data. | Bursty workloads, prototyping, collaborative projects, or lacking local infrastructure. |
Table 2: Estimated Runtime & Cost for a Standard CataPro Training Epoch
| Hardware Configuration | Estimated Time per Epoch* | Local Cluster Cost (Amortized) | Cloud Service Cost (On-Demand) |
|---|---|---|---|
| 4x NVIDIA V100 (32GB) | ~4.5 hours | ~$85 (infra + power) | ~$90 - $110 |
| 8x NVIDIA A100 (80GB) | ~1.8 hours | ~$190 (infra + power) | ~$140 - $170 |
| 1x NVIDIA H100 (80GB) | ~2.2 hours | N/A (rare on-prem) | ~$95 - $120 |
*Based on a dataset of 500k enzyme-kinetics pairs.
Experimental Protocols
Protocol 1: Deploying and Benchmarking CataPro on a Local Slurm Cluster
Objective: To establish a reproducible, high-performance workflow for training the CataPro model on an on-premises Slurm-managed HPC cluster.
Materials: See "Scientist's Toolkit" below.
Procedure:
- Environment Setup: On the cluster login node, use Conda to create a virtual environment:
conda create -n catapro python=3.10 pytorch=2.0 cudatoolkit=11.8 -c pytorch. - Software Installation: Activate the environment (
conda activate catapro) and install additional dependencies:pip install -r requirements.txt(including DeepSpeed, Weights & Biases for logging). - Data Staging: Transfer the curated enzyme kinetics dataset to the cluster's high-performance parallel filesystem (e.g., Lustre, GPFS). Verify data integrity using checksums.
- Job Script Preparation: Create a Slurm submission script (
run_catapro.slurm):
- Submission & Monitoring: Submit the job:
sbatch run_catapro.slurm. Monitor via squeue -u $USER. Use sacct for job efficiency statistics.
- Benchmarking: Record key metrics: Time to completion, GPU utilization (
nvidia-smi logs), memory usage, and cost amortized over the cluster's total cost of ownership.
Protocol 2: Orchestrating Distributed CataPro Training on AWS Cloud
Objective: To launch a scalable, fault-tolerant CataPro training job using AWS ParallelCluster and Kubernetes (EKS) for hyperparameter optimization.
Materials: See "Scientist's Toolkit" below.
Procedure:
- Infrastructure as Code (IaC): Define the cluster using AWS ParallelCluster config YAML, specifying a head node and multiple GPU-equipped compute nodes (e.g., p4d.24xlarge instances).
- Data Pipeline: Upload the preprocessed dataset to an Amazon S3 bucket. Configure an FSx for Lustre filesystem linked to the S3 bucket for high-throughput access from compute instances.
- Containerization: Build a Docker image containing the CataPro code, dependencies, and optimized PyTorch libraries. Push the image to Amazon Elastic Container Registry (ECR).
- Job Orchestration (EKS Path):
a. Create an EKS cluster with GPU node groups.
b. Deploy a
TrainingJob custom resource or use a Job manifest in Kubernetes, specifying the Docker image, number of replicas (GPUs), and the mounted FSx volume.
c. Use kubectl to apply the manifest and monitor pod logs.
- Hyperparameter Sweep: Integrate with AWS Step Functions or use Ray Tune within the Kubernetes pods to manage parallel experiments across different learning rates, batch sizes, and model dimensions.
- Cost Monitoring: Activate AWS Budgets and Cost Explorer with alerts. Use instance spot fleets for >70% cost reduction, with checkpointing to handle potential interruption.
Mandatory Visualizations
Diagram 1: CataPro Training Resource Decision Workflow
Diagram 2: Cloud Training Architecture for CataPro
The Scientist's Toolkit
Table 3: Essential Research Reagent Solutions & Materials
Item
Function in CataPro Research
Example/Note
Curated Enzyme Kinetics Dataset
The foundational training and validation data linking enzyme sequences/structures to kinetic parameters (kcat, KM).
Proprietary or public datasets (e.g., BRENDA, SABIO-RK) require extensive cleaning and featurization.
PyTorch / DeepSpeed Framework
Core deep learning libraries enabling model definition, distributed training, and mixed-precision optimization.
DeepSpeed ZeRO-2/3 is critical for efficiently scaling to billions of parameters.
NVIDIA GPU Accelerators
Hardware for massively parallel matrix operations essential for neural network training.
A100/H100 GPUs preferred for Tensor Core acceleration and large memory (>80GB).
Slurm Workload Manager
Job scheduler for managing computational resources on local HPC clusters.
Enables fair sharing, queue management, and efficient hardware utilization.
Docker / Singularity
Containerization platforms for encapsulating the complete software environment, ensuring reproducibility.
Singularity is common in HPC; Docker dominates in cloud environments.
Weights & Biases (W&B) / MLflow
Experiment tracking tools to log hyperparameters, metrics, and model artifacts across all runs.
Vital for comparing cloud vs. local performance and maintaining reproducibility.
High-Performance Parallel Filesystem
Storage system for low-latency, high-throughput access to large datasets during multi-GPU training.
Local: Lustre, GPFS. Cloud: AWS FSx for Lustre, Google Filestore.
CI/CD Pipeline (GitHub Actions)
Automated testing and deployment of model code changes, integrating with both local and cloud runners.
Ensures model updates are consistently validated before large-scale training.
Benchmarking CataPro: How It Stacks Up Against Experimental and Computational Methods
1. Introduction & Thesis Context Within the broader thesis on the CataPro deep learning model for enzyme kinetics prediction, establishing a robust validation gold standard is paramount. This document details application notes and protocols for evaluating CataPro's generalizability and predictive power beyond its training data, focusing on performance across curated blind test sets and independent published benchmarks.
2. Quantitative Performance Summary Table 1: CataPro Performance on Internal Blind Test Sets
| Test Set Description | Size (Enzyme-Substrate Pairs) | Key Metric (kcat/KM) | CataPro Performance (Pearson's r) | Baseline Model Performance (Pearson's r) |
|---|---|---|---|---|
| Phylogenetic Hold-Out (Dist. Families) | 1,245 | log10(kcat/KM) | 0.78 ± 0.03 | 0.52 ± 0.05 |
| Novel Substrate Scaffolds | 587 | log10(kcat/KM) | 0.71 ± 0.04 | 0.48 ± 0.06 |
| Multi-Species Orthologs | 912 | ΔΔG‡ (Activation Energy) | 0.69 ± 0.04 | 0.41 ± 0.07 |
Table 2: Performance on External Published Benchmarks
| Benchmark Dataset (Source) | Target Property | CataPro MAE/RMSE | State-of-the-Art Benchmark MAE/RMSE (Literature) |
|---|---|---|---|
| S. nuclease catalysis rates (Bar-Even et al., 2011) | log10(kcat) | MAE = 0.82 log units | MAE = 1.15 log units (MLR Model) |
| EnzDP Hydrolase kcat (Li et al., 2022) | log10(kcat) | RMSE = 1.28 log units | RMSE = 1.67 log units (EnzDP) |
| ProtaBank AMINO kcat/KM (Brandes et al., 2022) | log10(kcat/KM) | Pearson's r = 0.65 | Pearson's r = 0.59 (Random Forest) |
3. Experimental Protocols Protocol 3.1: Execution of a Blind Test Set Prediction Objective: To use CataPro for predicting kinetic parameters on a held-out set of enzyme sequences and substrate structures. Materials: See The Scientist's Toolkit below. Procedure:
- Data Preparation: Load the blind test set file (FASTA for enzymes, SMILES for substrates). Ensure no overlap with training/validation sets.
- Feature Generation:
a. For enzymes, run the CataPro-provided
embed_sequence.pyscript to generate pre-trained evolutionary-scale representations. b. For substrates, use thesubstrate_descriptor.pymodule to compute quantum chemical and topological fingerprints. - Model Inference: Execute the CataPro prediction pipeline:
catapro_predict --enzyme_embeddings emb.pt --substrate_descriptors desc.npy --output predictions.csv. - Post-processing: The output (
predictions.csv) contains predicted log10(kcat), log10(KM), and log10(kcat/KM). Apply inverse transformation if using normalized values. - Validation: Compare predictions to experimental ground truth using statistical scripts (
calc_metrics.py) to compute Pearson's r, MAE, and RMSE.
Protocol 3.2: Benchmarking Against External Datasets Objective: To independently validate CataPro on publicly available datasets from literature. Procedure:
- Benchmark Curation: Download the external dataset. Standardize units to s⁻¹ for kcat and M for KM. Map all entries to canonical enzyme (UniProt ID) and substrate (InChI Key) identifiers.
- Data Alignment & Filtering: Use CataPro's alignment tool (
align_to_train.py) to identify and report any sequence or structural similarity between benchmark entries and CataPro's training corpus, filtering as required for a strict test. - Prediction & Analysis: Follow Protocol 3.1 Steps 2-5. Generate parity plots and error distribution histograms using the provided
plot_utilsmodule.
4. Visualizations
Title: CataPro Validation Workflow & Data Sources
Title: Thesis Context of Validation Strategy
5. The Scientist's Toolkit: Research Reagent Solutions Table 3: Essential Materials & Tools for CataPro Validation
| Item | Function/Description |
|---|---|
| CataPro Software Suite (v2.1+) | Core deep learning model and prediction pipelines. |
| Pre-computed Enzyme Embeddings | Evolutionary context-aware protein representations from the model's encoder. |
| Substrate Fingerprint Library | Pre-configured quantum chemical (e.g., DFT-based) and molecular descriptor calculators. |
| Standardized Blind Test Sets | Curated .csv files with paired enzyme sequences, substrate SMILES, and experimental kinetic parameters. |
| Benchmark Curation Scripts | Python tools for mapping and filtering external datasets to prevent data leakage. |
Statistical Analysis Module (calc_metrics.py) |
Scripts for calculating Pearson's r, MAE, RMSE, and generating publication-ready plots. |
| High-Performance Computing (HPC) Node | GPU-accelerated environment (recommended: NVIDIA A100, 40GB VRAM) for batch inference on large sets. |
Application Notes
Within the ongoing thesis research on the CataPro deep learning model for enzyme kinetics prediction, a critical performance benchmark was conducted. This analysis compared CataPro against two established computational approaches: Traditional Quantitative Structure-Activity Relationship (QSAR) modeling and detailed Mechanistic (kinetic) Modeling. The objective was to quantify relative performance in predicting key enzyme kinetic parameters (kcat, KM) for a diverse test set of 150 enzyme-ligand pairs derived from publicly available databases like BRENDA and the literature.
Key Findings:
- Accuracy: CataPro demonstrated superior predictive accuracy, particularly for novel substrate scaffolds not represented in training data, reducing the mean absolute percentage error (MAPE) for kcat prediction by over 40% compared to the best traditional QSAR model.
- Speed: Once trained, CataPro's inference time for a new molecule is orders of magnitude faster than running a full mechanistic simulation, enabling high-throughput virtual screening.
- Data Dependency: Traditional QSAR models showed high performance on congeneric series but failed dramatically on structurally distinct molecules. Mechanistic models were highly accurate when precise kinetic mechanisms and parameters were known but were inapplicable to novel systems without extensive experimental characterization.
- Interpretability Trade-off: While mechanistic models provide explicit, interpretable reaction steps, and QSAR offers descriptor importance, CataPro's deep learning architecture acts as a "black box," though gradient-based attribution methods can provide post-hoc insights.
Conclusion: CataPro represents a paradigm shift, offering a favorable balance of high accuracy and speed for de novo enzyme kinetic prediction, effectively bridging the gap between rapid-but-fragile QSAR and accurate-but-slow mechanistic modeling. It is positioned as a powerful tool for early-stage drug metabolism prediction and enzyme engineering.
Table 1: Model Performance Comparison on Enzyme Kinetic Parameter Prediction
| Model Category | Specific Model/Type | Avg. MAPE (kcat) | Avg. MAPE (KM) | Avg. Inference Time per Compound | Data Requirement Scale | Applicability to Novel Scaffolds |
|---|---|---|---|---|---|---|
| Deep Learning | CataPro (This Thesis) | 18.7% | 22.3% | < 1 second | High (Large, diverse datasets) | Excellent |
| Traditional QSAR | Random Forest (ECFP6) | 32.5% | 41.8% | ~1-2 seconds | Medium (Homologous series) | Poor |
| Traditional QSAR | Support Vector Machine (RDKit) | 35.1% | 45.6% | ~3-5 seconds | Medium (Homologous series) | Poor |
| Mechanistic Modeling | Full Kinetic Simulation (COPASI) | 10.5%* | 12.1%* | ~10 minutes to hours | Very High (Mechanism & rate constants) | Very Poor |
Performance for mechanistic modeling is achievable only when the correct catalytic mechanism and all elementary rate constants are known *a priori.
Table 2: Computational Resource Requirements for Model Training/Setup
| Requirement | CataPro Deep Learning | Traditional QSAR | Mechanistic Modeling |
|---|---|---|---|
| Primary Hardware | GPU (e.g., NVIDIA A100) | CPU | CPU |
| Typical Setup/ Training Time | 24-48 hours (training) | 1-2 hours (hyperparameter tuning) | Days-Weeks (mechanism elucidation, parameter fitting) |
| Key Software | PyTorch, RDKit, CUDA | Scikit-learn, RDKit, MOE | COPASI, MATLAB, Berkeley Madonna |
| Output | Direct kcat, KM prediction | Statistical activity correlation | Dynamic time-course simulation |
Experimental Protocols
Protocol 1: Benchmark Dataset Curation for CataPro Validation Objective: To assemble a standardized, high-quality dataset for head-to-head model comparison.
- Source Data Extraction: Query the BRENDA and UniProt databases for enzymes with experimentally validated kcat and KM values. Use the RCSB PDB to identify entries with co-crystallized ligands.
- Data Curation: Filter entries to ensure:
- Kinetic parameters are associated with a specific substrate and enzyme source.
- pH and temperature are recorded.
- The substrate SMILES string is obtainable or can be accurately derived from the PDB ligand (using RDKit).
- Stratified Splitting: Divide the final dataset (150 pairs) into a training set (100 pairs) for traditional QSAR model development, a validation set (25 pairs) for CataPro hyperparameter tuning, and a held-out test set (25 pairs) for final, unbiased benchmarking. Ensure splits maintain structural diversity using scaffold-based clustering (Butina algorithm in RDKit).
- Descriptor/Feature Generation: For QSAR models, generate molecular descriptors (e.g., MOE descriptors) and fingerprints (ECFP6, MACCS keys) using RDKit.
Protocol 2: Training and Evaluating a Comparative Random Forest QSAR Model Objective: To establish a performance baseline using a robust traditional QSAR method.
- Feature Preparation: From Protocol 1, use the 100-pair training set. Standardize all molecular descriptors (z-score normalization).
- Model Training: Employ
scikit-learn'sRandomForestRegressor. Initially perform a grid search (5-fold cross-validation on the training set) to optimize hyperparameters (nestimators, maxdepth, minsamplessplit). - Validation: Apply the optimized model to the validation set (25 pairs) to check for overfitting.
- Benchmark Testing: Apply the final model to the held-out 25-pair test set. Calculate performance metrics (Mean Absolute Error, Mean Absolute Percentage Error, R²) for kcat and KM predictions. Record inference times.
Protocol 3: CataPro Model Inference and Attribution Analysis Objective: To execute predictions with the pre-trained CataPro model and probe its decision-making.
- Model Loading: Load the pre-trained CataPro model (PyTorch
.ptfile) in an inference environment. - Input Encoding: For a given test substrate SMILES, generate the required graph representation (atom features, bond adjacency) using the model's proprietary featurizer (based on D-MPNN architecture).
- Prediction: Pass the encoded substrate graph and the target enzyme's learned embedding vector through the CataPro network to obtain predicted log(kcat) and log(KM) values.
- Attribution (Saliency): Use an integrated gradients method (
Captumlibrary) to calculate the contribution of each atom in the input substrate to the final predicted kinetic parameter. Visualize the saliency map overlaid on the 2D molecular structure. - Benchmarking: Repeat for all compounds in the test set, aggregate metrics, and compare to Tables 1 & 2.
Visualizations
Diagram Title: Comparative Workflows for Kinetic Prediction
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials & Tools for Enzyme Kinetics Prediction Research
| Item | Category | Function/Brief Explanation |
|---|---|---|
| BRENDA Database | Data Resource | Comprehensive enzyme functional data repository for sourcing experimental kinetic parameters (kcat, KM). |
| RCSB Protein Data Bank (PDB) | Data Resource | Provides 3D structural data for enzymes and enzyme-ligand complexes, crucial for structure-based featurization. |
| RDKit | Software/Chemoinformatics | Open-source toolkit for cheminformatics (SMILES parsing, fingerprint generation, molecular descriptor calculation). |
| COPASI | Software/Modeling | Platform for simulating and analyzing biochemical reaction networks via mechanistic ordinary differential equations. |
| PyTorch / TensorFlow | Software/Deep Learning | Frameworks for building, training, and deploying deep neural networks like CataPro. |
| scikit-learn | Software/ML | Library for implementing traditional machine learning models (e.g., Random Forest, SVM) for QSAR. |
| NVIDIA GPU (e.g., A100) | Hardware | Accelerates the training and inference of large deep learning models, reducing time from weeks to days/hours. |
| Integrated Gradients (Captum) | Software/Analysis | Model interpretability library for attributing predictions to input features, offering insight into "black box" models. |
| Molecular Operating Environment (MOE) | Software/Chemoinformatics | Commercial suite offering advanced molecular modeling, simulation, and a broad set of molecular descriptors. |
Application Notes
The prediction of enzyme function from sequence and structural data is a critical task in biochemistry, metabolic engineering, and drug discovery. Several deep learning models have emerged as specialized tools within this domain. Framed within a broader thesis on the CataPro model for enzyme kinetics prediction, this document compares key models, detailing their applications, strengths, and limitations.
CataPro is a deep learning model explicitly designed for the prediction of enzyme catalytic properties, including turnover number (kcat) and Michaelis constants (KM). It utilizes protein language model embeddings (from ESM-2) and graph neural networks (GNNs) operating on 3D enzyme structures to learn complex structure-function relationships for kinetic parameter prediction. Its primary application is in systems biology and enzyme engineering, where quantitative kinetics are required.
DeepEC is a convolutional neural network (CNN)-based tool that predicts Enzyme Commission (EC) numbers from protein sequence alone. It employs an ensemble of CNNs to translate protein sequences into their likely enzymatic function (EC number). It is a high-throughput tool for functional annotation but does not provide quantitative kinetic parameters.
CLEAN (Contrastive Learning–enabled Enzyme Annotation) is a contrastive learning model that also predicts EC numbers. It learns a continuous, meaningful similarity metric between enzymes, allowing for accurate function prediction and discovery of novel enzymatic functions. It operates on sequence data and excels at identifying functional similarities beyond strict EC classification.
Table 1: Quantitative Comparison of Deep Learning Models for Enzyme Function
| Feature | CataPro | DeepEC | CLEAN |
|---|---|---|---|
| Primary Prediction | Catalytic parameters (kcat, KM) | EC Number | EC Number & Functional Similarity |
| Input Data | Protein Sequence + 3D Structure | Protein Sequence | Protein Sequence |
| Core Architecture | Protein LM + Structure GNN | Ensemble of CNNs | Contrastive Learning (Especially with ESM) |
| Key Output | Continuous kinetic values | Discrete EC class | Similarity score & EC class |
| Typical Use Case | Kinetic modeling, enzyme engineering | High-throughput genome annotation | Novel enzyme discovery, detailed function inference |
Table 2: Performance Benchmarks on Public Datasets
| Model | Benchmark Dataset | Key Metric | Reported Performance |
|---|---|---|---|
| CataPro | Catabolic | Test RMSE for log10(kcat) | ~0.69 |
| DeepEC | EnzymeNet | F1-score (EC number prediction) | >0.95 |
| CLEAN | UniProt/Swiss-Prot | Precision-Recall AUC (Novel function) | >0.99 |
Experimental Protocols
Protocol 1: Predicting Enzyme Kinetics Using CataPro
This protocol details the steps for predicting the turnover number (kcat) for a wild-type enzyme using the CataPro model.
1. Input Preparation:
- Sequence File: Obtain the amino acid sequence of the target enzyme in FASTA format.
- Structure File: Generate or obtain a 3D protein structure file (.pdb format). This can be an experimentally solved structure or a high-quality predicted structure from AlphaFold2 or RoseTTAFold.
2. Structure Preprocessing:
- Use Biopython or OpenBabel to remove heteroatoms (water, ligands, ions) from the .pdb file, retaining only the protein atoms.
- Ensure the structure file contains only standard amino acids.
3. Feature Generation with CataPro Scripts:
- Run the provided CataPro feature generation script. This will:
- Compute ESM-2 embeddings for the input sequence.
- Process the 3D structure into a graph representation, extracting atomic and residue-level features.
- Command:
python generate_features.py --fasta sequence.fasta --pdb structure.pdb --output feature_set.pkl
4. Model Inference:
- Load the pre-trained CataPro model (PyTorch format).
- Load the generated
feature_set.pkl. - Execute the prediction script to obtain the predicted log10(kcat) value.
- Command:
python predict_kcat.py --model catapro_model.pt --features feature_set.pkl
5. Result Interpretation:
- The model output is log10(kcat / s⁻¹). Convert to kcat by raising 10 to the power of the output value.
Protocol 2: High-Throughput EC Number Annotation with DeepEC
This protocol describes batch annotation of protein sequences from a metagenomic study.
1. Input Sequence Preparation:
- Compile all protein sequences of interest into a single multi-FASTA file.
2. Running DeepEC:
- Install DeepEC via Docker for reproducibility.
- Execute the main prediction script, pointing to the input FASTA file and a designated output directory.
- Command:
python DeepEC.py --input metagenome_proteins.fasta --output ./deepec_results/
3. Parsing Output:
- The primary output file (
DeepEC_Result.txt) is a tab-separated file containing sequence ID, predicted EC number, and a confidence score. - Filter predictions based on a confidence threshold (e.g., >0.75) for downstream analysis.
Protocol 3: Identifying Novel Enzyme Functions with CLEAN
This protocol uses CLEAN to find enzymes in a custom database that are functionally similar to a query enzyme of interest.
1. Database and Query Setup:
- Format your custom protein sequence database as a FASTA file.
- Prepare the query enzyme sequence as a separate FASTA file.
2. Computing Similarity Scores:
- Run the CLEAN
compare.pyscript to compute the contrastive learning similarity score between the query and every sequence in the database. - Command:
python clean/compare.py --query query.fasta --db custom_db.fasta --output scores.tsv
3. Analysis of Hits:
- Sort the
scores.tsvfile by descending similarity score. - High-scoring hits (>0.9) likely share detailed mechanistic function with the query, even if their EC numbers differ.
- Manually inspect top hits for plausible novel functional annotations.
Visualizations
CataPro Model Prediction Workflow
Core Model Inputs and Outputs Comparison
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Resources for In Silico Enzyme Function Analysis
| Resource / Tool | Function / Purpose | Source / Example |
|---|---|---|
| AlphaFold2 Protein Structure Database | Provides high-accuracy predicted 3D structures for proteins lacking experimental structures, essential for structure-based models like CataPro. | EMBL-EBI / UniProt |
| ESM-2 Protein Language Model | Generates contextual, evolutionarily informed embeddings from amino acid sequences; used as input features by CataPro and CLEAN. | Meta AI (Facebook Research) |
| PyTorch / TensorFlow | Deep learning frameworks required for running model inference and, optionally, fine-tuning models on proprietary data. | Open Source (PyTorch.org, TensorFlow.org) |
| Docker Containers | Ensures computational reproducibility by packaging model code, dependencies, and environment into a single executable unit. | Docker Hub (e.g., DeepEC image) |
| BRENDA Database | Comprehensive enzyme kinetics database; used as a gold-standard source for training data and for benchmarking predictions. | BRENDA Enzyme Database |
| Biopython Library | Toolkit for biological computation; used for parsing FASTA/PDB files, sequence manipulation, and interfacing with prediction tools. | Biopython.org |
Application Note AN-2024-001: Accelerated Lead Optimization for Kinase Inhibitors
Thesis Context: Integration of the CataPro deep learning model for predicting enzyme inhibition constants (Ki) and catalytic efficiency (kcat/KM) has revolutionized early-stage hit-to-lead optimization, drastically reducing the cycle time for biochemical assay prioritization.
Case Study 1: Pan-JAK Kinase Selectivity Profiling
- Traditional Approach: Experimental kinetic characterization of 150 novel compounds against 4 JAK kinase isoforms required expressed/purified protein for each isoform. Each compound's Ki determination via dose-response ITC or radiometric assays took approximately 3.5 days of hands-on time. Total project timeline: 18 months; estimated cost: $425,000 (reagents, labor, instrumentation).
- CataPro-Integrated Workflow: Compound structures were input into CataPro for in silico Ki prediction against all 4 isoforms. The top 30 candidates with predicted desirable selectivity profiles were selected for experimental validation. Experimental timeline: 4.2 months; cost: $98,000.
Table 1: Quantitative Impact Summary for Kinase Inhibitor Development
| Metric | Traditional Workflow | CataPro-Integrated Workflow | Reduction |
|---|---|---|---|
| Total Compounds Tested | 150 | 30 (via prediction) | 80% |
| Experimental Timeline | 18 months | 4.2 months | 77% |
| Estimated Direct Cost | $425,000 | $98,000 | 77% |
| Key Savings Driver | N/A | Prioritization via in silico Ki/kcat prediction |
Protocol 1.1: CataPro-Guided Tiered Screening for Inhibitors
Objective: To rapidly identify and validate lead inhibitors for a target enzyme using a prediction-prioritized experimental cascade.
Materials & Workflow:
- Input Preparation: Generate SMILES strings for all compounds in the screening library.
- CataPro Prediction: Submit SMILES list and target enzyme UniProt ID to CataPro API. Retrieve predicted Ki and kcat/KM values.
- Tier 1 - In Silico Tier: Rank compounds by predicted potency (Ki) and selectivity (if multiple isoforms). Apply ligand efficiency and physicochemical property filters.
- Tier 2 - Primary Biochemical Assay: Express and purify target enzyme. Perform confirmatory dose-response activity assays (e.g., fluorescence-based) on top 2-5% of predicted hits.
- Tier 3 - Secondary Validation: Determine experimental Ki for confirmed hits using ITC or SPR.
- Data Integration: Feed experimental Ki values back into CataPro for model refinement.
Diagram 1: CataPro-integrated tiered screening workflow.
Application Note AN-2024-002: Streamlining Metabolic Pathway Engineering
Thesis Context: CataPro's accurate kcat predictions for non-native substrates enable in silico pathway flux analysis, minimizing the iterative "build-test-learn" cycles in metabolic engineering.
Case Study 2: Optimizing a Caffeine-to-Theobromine Bioconversion Pathway
- Traditional Approach: Screening 12 putative N-demethylase enzymes required heterologous expression in a host chassis, growth assays, and LC-MS product quantification for each variant. Each design-build-test cycle took 11 weeks. Achieving a >90% yield required 4 cycles (44 weeks).
- CataPro-Integrated Workflow: CataPro predicted kcat values for caffeine and pathway intermediates for all 12 enzymes and 50 designed mutants. The top 3 enzyme candidates with highest predicted pathway flux were engineered. The target yield was achieved in 1 cycle (11 weeks).
Table 2: Quantitative Impact Summary for Pathway Engineering
| Metric | Traditional Workflow | CataPro-Integrated Workflow | Reduction |
|---|---|---|---|
| Design-Build-Test Cycles | 4 cycles | 1 cycle | 75% |
| Project Timeline | 44 weeks | 11 weeks | 75% |
| Enzyme Variants Tested | 48 (12 x 4 cycles) | 3 | 94% |
| Key Savings Driver | N/A | In silico pathway flux prediction |
Protocol 2.1: In Silico Pathway Flux Prediction with CataPro
Objective: To select optimal enzyme variants for a multi-step biosynthetic pathway prior to experimental construction.
Materials & Workflow:
- Define Pathway: List all enzymatic steps (E1, E2...En) and chemical intermediates (S, P1, P2...Pfinal).
- Compile Enzyme Variants: Gather sequences for wild-type and mutant enzymes for each step.
- CataPro Substrate Prediction: For each enzyme variant, use CataPro to predict kcat for its intended substrate (e.g., Wild-type E1 on S, Mutant E1 on S).
- Build Flux Model: Incorporate predicted kcat values as Vmax parameters into a simple kinetic model (e.g., Michaelis-Menten) for each step. Use enzyme concentration as an adjustable parameter.
- Simulate & Rank: Simulate total pathway flux to desired product. Rank enzyme combination based on predicted yield/titer.
- Construct & Validate: Build only the top-ranked pathway in the microbial host for experimental validation.
Diagram 2: Workflow for predictive metabolic pathway design.
The Scientist's Toolkit: Key Research Reagent Solutions
Table 3: Essential Materials for Enzyme Kinetics & Validation Studies
| Item | Function in Protocol | Example Vendor/Product |
|---|---|---|
| Fluorescent ATP Analog (e.g., Kinase-Glo) | Enables homogeneous, non-radiometric measurement of kinase activity by quantifying ATP consumption. | Promega Kinase-Glo Max |
| Isothermal Titration Calorimetry (ITC) Kit | Provides pre-optimized buffers and standards for direct measurement of binding affinity (KD) and stoichiometry (n). | Malvern MicroCal PEAQ-ITC |
| Surface Plasmon Resonance (SPR) Chip (e.g., CMS) | Gold sensor chip functionalized with a carboxymethyl dextran matrix for immobilizing proteins/ligands for real-time binding kinetics. | Cytiva Series S CMS Chip |
| High-Throughput Expression & Purification System | Automated system for parallel cloning, expression, and purification of multiple enzyme variants (e.g., 24x). | Thermo Fisher KingFisher Flex |
| LC-MS/MS System with UNIFI | For quantifying substrate depletion/product formation in complex matrices (e.g., lysate) during pathway validation. | Waters ACQUITY UPLC / Xevo TQ-XS |
| CataPro API Access | Programmatic interface to submit batch queries (SMILES, sequences) and retrieve predicted kinetic parameters (Ki, KM, kcat). | Catalytic Prophecies Inc. |
Application Notes
CataPro, a deep learning model for enzyme kinetics prediction, demonstrates its greatest advantage in specific, complex project scopes where traditional kinetic modeling falls short. The model excels in integrating high-dimensional, heterogeneous datasets to predict catalytic parameters (kcat, KM) and infer mechanistic pathways. Current research (2024-2025) indicates its optimal application lies in projects characterized by sparse experimental data, complex multi-enzyme systems, and the need for rapid in silico screening.
Table 1: Comparative Advantage of CataPro Across Project Scopes
| Project Scope Characteristic | Traditional QSAR/Michaelis-Menten | CataPro Model Performance | Quantitative Advantage (Reported Range) |
|---|---|---|---|
| Sparse Kinetic Data Points (<5 substrate concentrations) | Poor extrapolation, high error | Robust prediction using pre-trained features | RMSE reduction in kcat: 40-60% |
| Multi-Enzyme Pathway Prediction | Sequential, isolated fitting | Integrated system kinetics | Pathway flux prediction accuracy: >85% |
| Novel Enzyme Function Annotation (from sequence) | Low specificity, mechanistic blind spots | Structure-aware kinetic inference | Correlation (r) between predicted/true KM: 0.75-0.82 |
| Allosteric/Non-Michaelis Kinetics | Requires explicit mechanistic model formulation | Implicit pattern recognition from dynamics data | Successful classification of mechanism type: 92% accuracy |
| High-Throughput Virtual Screening (105 variants) | Computationally prohibitive | Rapid batch prediction (milliseconds/variant) | Throughput increase: ~104x over MD simulations |
CataPro's architecture, which fuses graph neural networks (GNNs) on enzyme structures with transformers on sequence and kinetic data, provides a decisive edge in the above scenarios. Its pre-training on the curated "KinetiBase" corpus (approx. 1.2 million data points from BRENDA and recent literature as of 2024) enables transfer learning for under-characterized enzyme families.
Experimental Protocols
Protocol 1: Validating CataPro Advantage on Sparse Data Projects
Objective: To benchmark CataPro against non-linear regression for predicting full Michaelis-Menten curves from minimal initial rate data. Materials: See "Scientist's Toolkit" below. Procedure:
- Dataset Curation: Select 3 distinct enzyme families (e.g., serine proteases, kinases, cytochrome P450s). For each, compile 20 enzymes with fully characterized kinetic parameters (kcat, KM) from public databases.
- Data Sparsification: For each enzyme, synthetically generate initial rate (v0) data at only 4 substrate concentrations ([S]), simulating a realistic low-data scenario. Add 5% Gaussian noise.
- Traditional Fitting: Use a non-linear least-squares algorithm (e.g., Levenberg-Marquardt) to fit the Michaelis-Menten equation v0 = (Vmax[S])/(KM+[S]) to the 4-point dataset. Record fitted kcat (Vmax/[E]) and KM.
- CataPro Prediction: Input into CataPro: a) the enzyme's amino acid sequence, b) the 4-point [S] and v0 data, c) predicted 3D structure (from AlphaFold2). Run the pre-trained CataPro model (e.g.,
catapro.predict_sparse). - Validation & Comparison: Compare both sets of predicted parameters against the known, fully-characterized "ground truth" values. Calculate Root Mean Square Error (RMSE) and Pearson correlation coefficient (r) for each method.
Protocol 2: De Novo Pathway Kinetics Simulation
Objective: To predict the steady-state flux of a novel metabolic pathway using kinetic parameters predicted by CataPro for each constituent enzyme. Materials: See "Scientist's Toolkit." Procedure:
- Pathway Definition: Define a linear 5-enzyme pathway (A → B → C → D → E → F). Use enzyme sequences with no published kinetic data on the specified substrates.
- Individual Kinetic Prediction: For each enzymatic step, run CataPro's batch prediction module. Input: enzyme sequence, substrate SMILES string, and cofactor information. Output: Predicted kcat, KM, and optional turnover-limiting step descriptor.
- System Construction: Construct an ordinary differential equation (ODE) model using a simulator (e.g., COPASI). Populate the model with CataPro-predicted parameters for each reaction step.
- Simulation & Analysis: Run a time-course simulation with a fixed initial concentration of substrate A. Measure the steady-state production rate of product F and the intermediate metabolite profiles.
- Experimental Benchmarking (If Possible): Compare the in silico predicted pathway flux with an in vitro reconstituted pathway using purified enzymes, following established assay protocols.
Visualizations
Title: CataPro Workflow Advantage for Sparse Data
Title: De Novo Pathway Kinetics Simulation Workflow
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for Featured CataPro Validation Experiments
| Item Name | Supplier Examples (2024) | Function in Protocol |
|---|---|---|
| Recombinant Enzyme Libraries | Thermo Fisher (GeneArt), Twist Bioscience, in-house expression | Source of enzymes with known sequence but potentially uncharacterized kinetics for validation studies. |
| High-Throughput Assay Kits (e.g., NAD(P)H-coupled, fluorogenic) | Sigma-Aldrich (MAK kits), Promega (CellTiter-Glo), Cayman Chemical | Enable rapid generation of initial rate (v0) data at multiple substrate concentrations for model input and validation. |
| Microplate Readers (UV-Vis & Fluorescence) | BMG Labtech CLARIOstar, Tecan Spark, Agilent BioTek Synergy | Essential instrumentation for collecting the kinetic data used as both sparse input and ground truth. |
| AlphaFold2 Colab or Local Server | Google Colab (AF2), Local HPC installation | Generates reliable protein structure predictions from sequence, a key input modality for the CataPro GNN. |
| COPASI Software (or similar) | COPASI.org, SimBiology (MATLAB) | Platform for constructing and simulating ODE-based metabolic pathway models using CataPro-predicted parameters. |
| CataPro Software Package | Public GitHub repository (hypothetical: catapro-team/catapro), with Docker container. |
The core deep learning model providing the kinetic predictions via a standardized API or command-line interface. |
Conclusion
The CataPro deep learning model represents a paradigm shift in enzyme kinetics, transitioning from a purely experimental endeavor to a predictable, in silico-augmented science. By providing rapid, accurate kcat predictions, it addresses foundational challenges in metabolic modeling, target prioritization, and enzyme engineering. While considerations around data scarcity and model interpretability remain, the methodological workflows and optimization strategies outlined empower researchers to integrate CataPro effectively into their pipelines. As validated against experimental benchmarks, CataPro's comparative advantage lies in its speed and scalability, enabling the characterization of enzyme families at an unprecedented scale. The future implications are profound: CataPro paves the way for more predictive systems biology, accelerates the design of novel biocatalysts, and fundamentally streamlines the early stages of drug discovery by rapidly identifying and validating enzymatic targets. Continued development, focusing on broader substrate specificity and mutant effect prediction, will further cement its role as an indispensable tool in biomedical research.